Why Does Deep Learning Work ? If we could get a better handle on this, we could solve some very … More
Thoughts on Data Science, Machine Learning, and AI
Why Does Deep Learning Work ? If we could get a better handle on this, we could solve some very … More

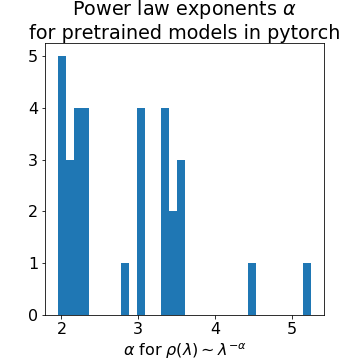
Why Deep Learning Works: Self Regularization in DNNs An early talk describing details in this paper Implicit Self-Regularization in Deep … More

I just got back from ICLR 2019 and presented 2 posters, (and Michael gave a great talk!) at the Theoretical … More

Please enjoy my video presentation on Geoff Hinton’s Capsule Networks. What they are, why they are important, and how they … More

My Labor Day Holiday Blog: for those on email, I will add updates, answer questions, and make corrections over the … More
Hinton introduced Free Energies in his 1994 paper, Autoencoders, minimum description length, and Helmholtz Free Energy This paper, along with … More

It’s always fun to be interviewed. Check out my recent chat with Max Mautner, the Accidental Engineer http://theaccidentalengineer.com/charles-martin-principal-consultant-calculation-consulting/
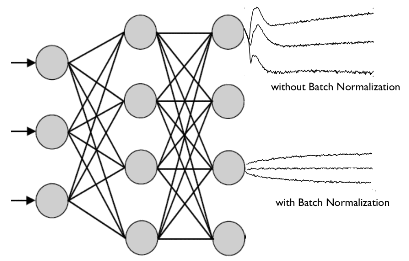
A few days ago (Jun 2017), a 100 page on Self-Normalizing Networks appeared. An amazing piece of theoretical work, it … More
?Deep Learning is presented as Energy-Based Learning Indeed, we train a neural network by running BackProp, thereby minimizing the model error–which is … More
A friend from grad school pointed out a great foundational paper on Boltzmann Machines. It is a 1987 paper from … More
