My Labor Day Holiday Blog: for those on email, I will add updates, answer questions, and make corrections over the next couple weeks. Thanks for reading and enjoy ! Wubba dub dub.
My graduate advisor used to say:
“If you can’t invent something new, invent your own notation”
Varitional Inference is foundational to Unsupervised and Semi-Supervised Deep Learning. In particular, Variational Auto Encoders (VAEs). There are many, many tutorials and implementations on Variational Inference, which I collect on my YouTube channel and below in the references. In particular, I look at modern ideas coming out of Google Deep Mind.
The thing is, Variational inference comes in 5 or 6 different flavors, and it is a lot of work just to keep all the notation straight.
We can trace the basic idea back to Hinton and Zemel (1994)– to minimize a Helmholtz Free Energy.
What is missing is how Variational Inference is related the Variational Free Energy from statistical physics. Or even how an RBM Free Energy is related to a Variational Free Energy.
This holiday weekend, I hope to review these methods and to clear some of this up. This is a long post filled with math and physics–enjoy !
Generating Functions
Years ago I lived in Boca Raton, Florida to be near my uncle, who was retired and on his last legs. I was working with the famous George White, one of the Dealers of Lightening, from the famous Xerox Parc. One day George stopped by to say hi, and he found me hanging out at the local Wendy’s and reading the book Generating Functionology. It’s a great book. And even more relevant today.
The Free Energy, 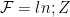
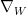
Let’s see how it all ties together.
Inference in RBMs
We first review inference in RBMs, which is one of the few Deep Learning examples that is fully expressed with classical Statistical Mechanics.
Suppose we have some (unlabeled) data 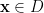
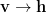
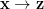
Before we begin, let us try to keep the notation straight. To compare different methods, I need to mix the notation a bit, and may be a little sloppy sometimes. Here, I may interchange the RBM and VAE conventions
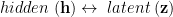
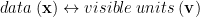
and, WLOG, may interchange the log functions
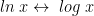
and drop the parameters on the distributions
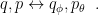
Also, the stat mech Physics Free Energy convention is the negative log Z,

and I sometimes use the bra-ket notation for expectation values
![\mathbb{E}[x]=\langle x\rangle\;](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bx%5D%3D%5Clangle+x%5Crangle%5C%3B&bg=ffffff&fg=%23000000&s=0&c=20201002)
Finally I might mix up the minus signs in the early draft of this blog; please let me know.
In an RBM, we learn an Energy function $, explicitly:
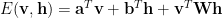
Inference means gradient learning. along the variational parameters ![\theta=[\mathbf{a},\mathbf{b}, \mathbf{W}]](https://s0.wp.com/latex.php?latex=%5Ctheta%3D%5B%5Cmathbf%7Ba%7D%2C%5Cmathbf%7Bb%7D%2C+%5Cmathbf%7BW%7D%5D&bg=ffffff&fg=%23000000&s=0&c=20201002)
![\nabla_{\theta}\mathbb{E}[log\;p(\mathbf{x})]](https://s0.wp.com/latex.php?latex=%5Cnabla_%7B%5Ctheta%7D%5Cmathbb%7BE%7D%5Blog%5C%3Bp%28%5Cmathbf%7Bx%7D%29%5D&bg=ffffff&fg=%23000000&s=0&c=20201002)
This is actually a form of Free Energy minimization. Let’s see why…
The joint probability is given by a Boltzmann distribution
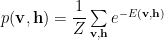
To get 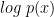


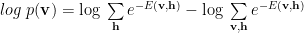
log likelihood = – clamped Free Energy + equilibrium Free Energy
(note the minus sign convention)
We recognize the second term as the total, or equilibrium, Free Energy from the partition function 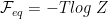
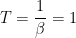
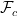
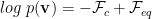
We see that the partition function Z is not just the normalization–it is a generating function. In statistical thermodynamics, derivatives of 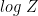
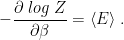
Since 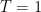
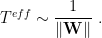
So if we take weight gradients 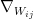
The gradients of the clamped Free Energy give an expectation value over the conditional

![\nabla_{\theta}\mathcal{F}_{c}=\mathbb{E}_{p(\mathbf{h}|\mathbf{v})}[\mathbf{h}^{T}\mathbf{v}]\;,](https://s0.wp.com/latex.php?latex=%5Cnabla_%7B%5Ctheta%7D%5Cmathcal%7BF%7D_%7Bc%7D%3D%5Cmathbb%7BE%7D_%7Bp%28%5Cmathbf%7Bh%7D%7C%5Cmathbf%7Bv%7D%29%7D%5B%5Cmathbf%7Bh%7D%5E%7BT%7D%5Cmathbf%7Bv%7D%5D%5C%3B%2C&bg=ffffff&fg=%23000000&s=0&c=20201002)
and the equilibrium Free Energy gradient yields an expectation of the joint distribution 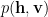
![\nabla_{\theta}\mathcal{F}_{eq}=\mathbb{E}_{p(\mathbf{h},\mathbf{v})}[\mathbf{h}^{T}\mathbf{v}]\;.](https://s0.wp.com/latex.php?latex=%5Cnabla_%7B%5Ctheta%7D%5Cmathcal%7BF%7D_%7Beq%7D%3D%5Cmathbb%7BE%7D_%7Bp%28%5Cmathbf%7Bh%7D%2C%5Cmathbf%7Bv%7D%29%7D%5B%5Cmathbf%7Bh%7D%5E%7BT%7D%5Cmathbf%7Bv%7D%5D%5C%3B.&bg=ffffff&fg=%23000000&s=0&c=20201002)
The derivatives do resemble expected Energies, with a unit weight matrix 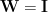
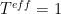
The clamped Free Energy is easy to evaluate numerically, but the equilibrium distribution is intractable. Hinton’s approach, Contrastive Divergence, takes a point estimate
![\mathbb{E}_{p(\mathbf{h},\mathbf{v})}[\mathbf{h}^{T}\mathbf{v}]\sim\bar{\mathbf{h}}^{T}\bar{\mathbf{v}}\;](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7Bp%28%5Cmathbf%7Bh%7D%2C%5Cmathbf%7Bv%7D%29%7D%5B%5Cmathbf%7Bh%7D%5E%7BT%7D%5Cmathbf%7Bv%7D%5D%5Csim%5Cbar%7B%5Cmathbf%7Bh%7D%7D%5E%7BT%7D%5Cbar%7B%5Cmathbf%7Bv%7D%7D%5C%3B&bg=ffffff&fg=%23000000&s=0&c=20201002)
where 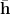

Free Energy Approximations
Unsupervised learning appears to be a problem in statistical mechanics — to evaluate the equilibrium partition function. There are lots of methods here to consider, including
- Monte Carlo, which is too hard computationally, and has too high variance
- Gibbs sampling + a point estimate, the Hinton CD solution
- Variational inference using the Kullback-Leibler bound and the reparameterization trick
- Importance, Umbrella sampling, a classic method from computational chemistry
- Deterministic fixed point equations, such as the TAP theory behind the EMF-RBM
- (Simple) Perturbation theory, yielding a cumulant expansion
- and lots of other methods (Laplace approximation, Stochastic Langevin Dynamics, Hamiltonian Dynamics, etc.)
Not to mention the very successful Deep Learning approach, which appears to be to simply guess, and then learn deterministic fixed point equations (i.e. SegNet) , via Convolutional AutoEncoders.
Unsupervised Deep Learning today looks like an advanced graduate curriculum in non-equilibirum statistical mechanics, all coded up in tensorflow.
We would need a year or more of coursework to go through this all, but I will try to impart some flavor as to what is going on here.
Variational AutoEncoders
VAEs are a kind of generative deep learning model–they let us model and generate fake data. There are at least 10 different popular models right now, all easily implemented (see the links) in like tensorflow, keras, and Edward.
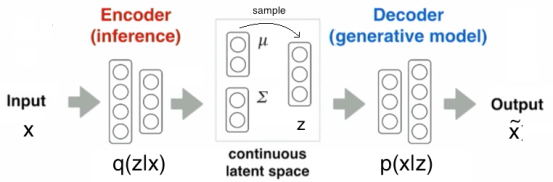
The vanilla VAE, ala Kingma and Welling, is foundational to unsupervised deep learning.
As in an RBM, in a VAE, we seek the joint probability 
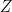

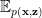
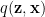
There are severals starting points although, in the end, we still end up minimizing a Free Energy. Let’s look at a few:
Score matching
This an autoencoder, so we are minimizing a something like a reconstruction error. We need is a score 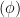

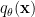
![min\;\mathbb{E}_{p(x)}[\;\Vert\phi(p)-\phi(q)\Vert^{2}\;]\;](https://s0.wp.com/latex.php?latex=min%5C%3B%5Cmathbb%7BE%7D_%7Bp%28x%29%7D%5B%5C%3B%5CVert%5Cphi%28p%29-%5Cphi%28q%29%5CVert%5E%7B2%7D%5C%3B%5D%5C%3B+&bg=ffffff&fg=%23000000&s=0&c=20201002)
This is a called score matching (2005). It has been shown to be closely related to auto-encoders.
I bring this up because if we look at supervised Deep Nets, and even unsupervised Nets like convolutional AutoEncoders, they are minimizing some kind of Energy or Free energy, implicitly at 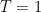
Expected log likelihood
We can also consider just minimizing the expected log likelihood, under the model
![min\;\mathbb{E}_{q}[log\;p(\mathbf{x})]\;](https://s0.wp.com/latex.php?latex=min%5C%3B%5Cmathbb%7BE%7D_%7Bq%7D%5Blog%5C%3Bp%28%5Cmathbf%7Bx%7D%29%5D%5C%3B+&bg=ffffff&fg=%23000000&s=0&c=20201002)
And with some re-arrangements, we can extract out a Helmholtz-like Free Energy. it is presented nicely in the Stanford class on Deep Learning, Lecture 13 on Generative Models.
Raise the Posteriors

We can also start by just minimizing the KL divergence between the posteriors
![min\;KL[q_{\phi}(\mathbf{x}|\mathbf{z})||p_{\theta}(\mathbf{x}|\mathbf{z})]](https://s0.wp.com/latex.php?latex=min%5C%3BKL%5Bq_%7B%5Cphi%7D%28%5Cmathbf%7Bx%7D%7C%5Cmathbf%7Bz%7D%29%7C%7Cp_%7B%5Ctheta%7D%28%5Cmathbf%7Bx%7D%7C%5Cmathbf%7Bz%7D%29%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
although we don’t actually minimize this KL divergence directly.
In fact, there is a great paper / video on Sequential VAEs which asks–are we trying to make q model p, or p model q ? The authors note that a good VAE, like a good RBM, should not just generate good data, but should also give a good latent representation 
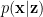

Variational Bayes
The most important paper in the field today is by Kigma and Welling,where they lay out the basics of VAEs. The video presentation is excellent also.
We form a continuous, Variational Lower Bound, which is a negative Free Energy (
![ln\;p(\mathbf{x})=\mathcal{L}_{q(\mathbf{z}|\mathbf{x})}(\mathbf{x})-KL[q_{\phi}(\mathbf{x}|\mathbf{z})||p_{\theta}(\mathbf{x}|\mathbf{z})]](https://s0.wp.com/latex.php?latex=ln%5C%3Bp%28%5Cmathbf%7Bx%7D%29%3D%5Cmathcal%7BL%7D_%7Bq%28%5Cmathbf%7Bz%7D%7C%5Cmathbf%7Bx%7D%29%7D%28%5Cmathbf%7Bx%7D%29-KL%5Bq_%7B%5Cphi%7D%28%5Cmathbf%7Bx%7D%7C%5Cmathbf%7Bz%7D%29%7C%7Cp_%7B%5Ctheta%7D%28%5Cmathbf%7Bx%7D%7C%5Cmathbf%7Bz%7D%29%5D&bg=ffffff&fg=%23000000&s=0&c=20201002)
And either minimizing the divergence of the posteriors, or maximizing the marginal likelihood, we end up minimizing a (negative) Variational Helmholtz Free Energy:
![-\mathcal{L}(\mathbf{x})=\mathbb{E}_{q_{\phi}(\mathbf{z}|\mathbf{x})}[log\;p_{\theta}(\mathbf{z},\mathbf{x}))-log\;q_{\phi}(\mathbf{z}|\mathbf{x})]](https://s0.wp.com/latex.php?latex=-%5Cmathcal%7BL%7D%28%5Cmathbf%7Bx%7D%29%3D%5Cmathbb%7BE%7D_%7Bq_%7B%5Cphi%7D%28%5Cmathbf%7Bz%7D%7C%5Cmathbf%7Bx%7D%29%7D%5Blog%5C%3Bp_%7B%5Ctheta%7D%28%5Cmathbf%7Bz%7D%2C%5Cmathbf%7Bx%7D%29%29-log%5C%3Bq_%7B%5Cphi%7D%28%5Cmathbf%7Bz%7D%7C%5Cmathbf%7Bx%7D%29%5D&bg=ffffff&fg=%23000000&s=0&c=20201002)
Free Energy = Expected Energy – Entropy
The Kullback-Leibler Variational Bound
There are numerous derivations of the bound, including the Stanford class and the original lecture by Kingma. The take-away-is
Maximizing the Variational Lower Bound minimizes the Free Energy
The Gibbs-Bogoliubov-Feymnann relation
 This is, again, actually an old idea from statistical mechanics, traced back to Feynman’s book (available in Hardback on Amazon for $1300!)
This is, again, actually an old idea from statistical mechanics, traced back to Feynman’s book (available in Hardback on Amazon for $1300!)
We make it sound fancy by giving it a Russian name, the Gibbs-Bogoliubov relation (described nice here). It is finite Temp generalization of the Rayleigh-Ritz theorem for the more familiar Hamiltonians 
The idea is to approximate the (Helmholtz) Free Energy with guess, model, or trial Free Energy 

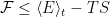
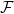
This is also very physically intuitive and reflects our knowledge of the fluctuation theorems of non-equilibrium stat mech. It says that any small fluctuation away equilibrium will relax back to equilibrium. In fact, this is a classic way to prove the variational bound…
and it introduces the idea of conservation of volume in phase space (i.e. the Liouville equation), which, I believe, is related to an Normalizing Flows for VAEs.But that is a future post.
Stochastic Gradients for VAEs
Stochastic gradient descent for VAEs is a deep subject; it is described in detail here
The gradient descent problem is to find the Free Energy gradient in the generative and variational parameters 
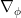
![\nabla_{\phi}\mathcal{L}()=\mathbb{E}_{q_{\phi}(\mathbf{z}|\mathbf{x})}[\nabla_{\phi}(\cdots)]](https://s0.wp.com/latex.php?latex=%5Cnabla_%7B%5Cphi%7D%5Cmathcal%7BL%7D%28%29%3D%5Cmathbb%7BE%7D_%7Bq_%7B%5Cphi%7D%28%5Cmathbf%7Bz%7D%7C%5Cmathbf%7Bx%7D%29%7D%5B%5Cnabla_%7B%5Cphi%7D%28%5Ccdots%29%5D&bg=ffffff&fg=%23000000&s=0&c=20201002)
This is not trivial since the expected value depends on the variational parameters. For the simple Free Energy objective above, we can show that
![\nabla_{\phi}\mathcal{L}(\phi)=\mathbb{E}_{q_{\phi}(\mathbf{z}|\mathbf{x})}[(\nabla_{\phi}\;log\;q_{\phi}(\mathbf{z}|\mathbf{x})(log\;p_{\theta}(\mathbf{x},\mathbf{z})-log\;q_{\phi}(\mathbf{z}|\mathbf{x}))]](https://s0.wp.com/latex.php?latex=%5Cnabla_%7B%5Cphi%7D%5Cmathcal%7BL%7D%28%5Cphi%29%3D%5Cmathbb%7BE%7D_%7Bq_%7B%5Cphi%7D%28%5Cmathbf%7Bz%7D%7C%5Cmathbf%7Bx%7D%29%7D%5B%28%5Cnabla_%7B%5Cphi%7D%5C%3Blog%5C%3Bq_%7B%5Cphi%7D%28%5Cmathbf%7Bz%7D%7C%5Cmathbf%7Bx%7D%29%28log%5C%3Bp_%7B%5Ctheta%7D%28%5Cmathbf%7Bx%7D%2C%5Cmathbf%7Bz%7D%29-log%5C%3Bq_%7B%5Cphi%7D%28%5Cmathbf%7Bz%7D%7C%5Cmathbf%7Bx%7D%29%29%5D&bg=ffffff&fg=%23000000&s=0&c=20201002)
Although we will make even further approximations to get working code.
We would like to apply BackProp to the variational lower bound; writing it in these 2 terms make this possible. We can evaluate the first term, the reconstruction error, using mini-batch SGD sampling, whereas the KL regularizer term is evaluated analytically.
We specify a tractable distribution 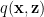
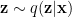
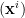
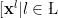
As in statistical physics, we do what we can, and take a mean field approximation. We then apply the reparameterization trick to let us apply BackProp. I review this briefly in the Appendix.
Statistical Physics and Variational Free Energies
This leads to several questions which I will adresss in this blog:
- How is this Free Energy related to log Z ?
- When is it variational ? When is it not ?
- How can it be systematically improved ?
- What is the relation to a deterministic, convolutional AutoEncoder ?
Like in Deep Learning, In almost all problems in statistical mechanics, we don’t know the actual Energy function, or Hamiltonian, 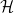
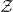
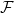
The Energy Representation
For a VAE, instead of trying to find the joint distribution 

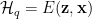
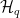
And, as in physics, q will also be a mean field approximation— but we don’t need that here.
Perturbation Theory
We decompose the total Hamiltonian into a model Hamiltonian Energy plus perturbation

Energy = Model + Perturbation
The perturbation is the difference between the true and model Energy functions, and assumed to be small in some sense. That is, we expect our initial guess to be pretty good already. Whatever that means. We have
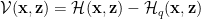
The constant $latex \lambda\le1&bg=ffffff$ is used to formally construct a power series (cumulant expansion); it is set to 1 at the end.
Write the equilibrium Free Energy in terms of the total Hamiltonian Energy function
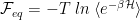
There are numerous expressions for the Free Energy–see the Appendix. From above, we have
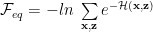
and we define equilibrium averages as
![\mathbb{E}_{eq}[f(\mathbf{x},\mathbf{z})]=\dfrac{1}{Z}\sum\limits_{\mathbf{x},\mathbf{z}}f(\mathbf{x},\mathbf{z})e^{-\mathcal{H(\mathbf{x},\mathbf{z})}}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7Beq%7D%5Bf%28%5Cmathbf%7Bx%7D%2C%5Cmathbf%7Bz%7D%29%5D%3D%5Cdfrac%7B1%7D%7BZ%7D%5Csum%5Climits_%7B%5Cmathbf%7Bx%7D%2C%5Cmathbf%7Bz%7D%7Df%28%5Cmathbf%7Bx%7D%2C%5Cmathbf%7Bz%7D%29e%5E%7B-%5Cmathcal%7BH%28%5Cmathbf%7Bx%7D%2C%5Cmathbf%7Bz%7D%29%7D%7D&bg=ffffff&fg=%23000000&s=0&c=20201002)
Recall we can not evaluate equilibrium averages, but we can presumably evaluate model averages ![\mathbb{E}_{q}[]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D_%7Bq%7D%5B%5D&bg=ffffff&fg=%23000000&s=0&c=20201002)
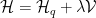
where 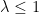

![\mathcal{F}_{eq}= -ln\;[\sum e^{\mathcal{H}_{q}-\lambda\mathcal{V}}]\;.](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BF%7D_%7Beq%7D%3D+-ln%5C%3B%5B%5Csum+e%5E%7B%5Cmathcal%7BH%7D_%7Bq%7D-%5Clambda%5Cmathcal%7BV%7D%7D%5D%5C%3B.&bg=ffffff&fg=%23000000&s=0&c=20201002)
Insert 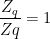

![\mathcal{F}_{eq}= -ln\;[\dfrac{\sum e^{-\mathcal{H}_{q}}}{\sum e^{-\mathcal{H}_{q}}}\sum e^{\mathcal{H}_{q}-\lambda\mathcal{V}}]\;.](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BF%7D_%7Beq%7D%3D+-ln%5C%3B%5B%5Cdfrac%7B%5Csum+e%5E%7B-%5Cmathcal%7BH%7D_%7Bq%7D%7D%7D%7B%5Csum+e%5E%7B-%5Cmathcal%7BH%7D_%7Bq%7D%7D%7D%5Csum+e%5E%7B%5Cmathcal%7BH%7D_%7Bq%7D-%5Clambda%5Cmathcal%7BV%7D%7D%5D%5C%3B.&bg=ffffff&fg=%23000000&s=0&c=20201002)
Using the property 

![\mathcal{F}_{eq}= -ln\;[\sum e^{-\mathcal{H}_{q}}]-ln\;\mathbb{E}_{q}[e^{-\mathcal{V}}]](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BF%7D_%7Beq%7D%3D+-ln%5C%3B%5B%5Csum+e%5E%7B-%5Cmathcal%7BH%7D_%7Bq%7D%7D%5D-ln%5C%3B%5Cmathbb%7BE%7D_%7Bq%7D%5Be%5E%7B-%5Cmathcal%7BV%7D%7D%5D&bg=ffffff&fg=%23000000&s=0&c=20201002)
This is formally exact–but hard to evaluate even with a tractable model.
We can approximate ![ln\;\mathbb{E}_{q}[e^{-\mathcal{V}}]](https://s0.wp.com/latex.php?latex=ln%5C%3B%5Cmathbb%7BE%7D_%7Bq%7D%5Be%5E%7B-%5Cmathcal%7BV%7D%7D%5D%C2%A0&bg=ffffff&fg=%23000000&s=0&c=20201002)
Cumulant Expansion
Cumulants can be defined most simply by a power series of the Cumulant generating function
![ln\;\mathbb{E}[e^{tx}]=t\mu+\dfrac{t^{2}}{2}\sigma^{2}+\cdots](https://s0.wp.com/latex.php?latex=ln%5C%3B%5Cmathbb%7BE%7D%5Be%5E%7Btx%7D%5D%3Dt%5Cmu%2B%5Cdfrac%7Bt%5E%7B2%7D%7D%7B2%7D%5Csigma%5E%7B2%7D%2B%5Ccdots+&bg=ffffff&fg=%23000000&s=0&c=20201002)
although it can be defined and applied more generally, and is a very powerful modeling tool.
As I warned you, I will use the bra-ket notation for expectations here, and switch to natural log
![ln\;\mathbb{E}[e^{tx}]=ln\;\langle e^{tx}\rangle](https://s0.wp.com/latex.php?latex=ln%5C%3B%5Cmathbb%7BE%7D%5Be%5E%7Btx%7D%5D%3Dln%5C%3B%5Clangle+e%5E%7Btx%7D%5Crangle+&bg=ffffff&fg=%23000000&s=0&c=20201002)
We immediately see that
the stat mech Free Energy has the form of a Cumulant generating function.
Being a generating function, the cumulants are generated by taking derivatives (as in this video), and expressed using double bra-ket notation.
The first cumulant is just the mean expected value
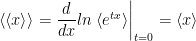
whereas the second cumulant is the variance–the “mean of square minus square of mean”

(yup, cumulants are so common in physics that they have their own bra-ket notation)
This a classic perturbative approximation. It is a weak-coupling expansion for the equilibrium Free Energy, appropriate for small 
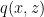

Kullback Leibler Free Energy and corrections
Since log expectation ![ln\;\mathbb{E}_{q}[e^{-\lambda\mathcal{V}}]](https://s0.wp.com/latex.php?latex=ln%5C%3B%5Cmathbb%7BE%7D_%7Bq%7D%5Be%5E%7B-%5Clambda%5Cmathcal%7BV%7D%7D%5D%C2%A0&bg=ffffff&fg=%23000000&s=0&c=20201002)
![\mathcal{F}_{eq}=-ln\;Z_{q}+\lambda\mathbb{E}_{q}[\mathcal{V}]-\dfrac{\lambda^{2}}{2}\mathbb{E}_{q}[\mathcal{V}-\mathbb{E}_{q}[\mathcal{V}]]^{2}+\cdots](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BF%7D_%7Beq%7D%3D-ln%5C%3BZ_%7Bq%7D%2B%5Clambda%5Cmathbb%7BE%7D_%7Bq%7D%5B%5Cmathcal%7BV%7D%5D-%5Cdfrac%7B%5Clambda%5E%7B2%7D%7D%7B2%7D%5Cmathbb%7BE%7D_%7Bq%7D%5B%5Cmathcal%7BV%7D-%5Cmathbb%7BE%7D_%7Bq%7D%5B%5Cmathcal%7BV%7D%5D%5D%5E%7B2%7D%2B%5Ccdots&bg=ffffff&fg=%23000000&s=0&c=20201002)
Setting 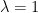
![\mathcal{F}_{q}=-ln\;Z_{q}+\lambda\mathbb{E}_{q}[\mathcal{V}]](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BF%7D_%7Bq%7D%3D-ln%5C%3BZ_%7Bq%7D%2B%5Clambda%5Cmathbb%7BE%7D_%7Bq%7D%5B%5Cmathcal%7BV%7D%5D&bg=ffffff&fg=%23000000&s=0&c=20201002)
The total equilibrium Free Energy is expressed as the model Free Energy plus perturbative corrections.

And now, for some
Final Comments and Summary
We now see the connection between the RBMs and VAEs, or, rather between the statistical physics formulation, with Energy and Partition functions, and the Bayesian probability formulation of VAEs.
Statistical mechanics has a very long history, over 100 years old, and there are many techniques now being lifted or rediscovered in Deep Learning, and then combined with new ideas. The post introduces the ideas being used today at Deep Mind, with some perspective from their origins, and some discussion about their utility and effectiveness brought from having seen and used these techniques in different contexts in theoretical chemistry and physics.
Cumulants vs TAP Theory
Of course, cumulants are not the only statistical physics tool. There are other Free Energy approximations, such as the TAP theory we used in the deterministic EMF-RBM.
Both the cumulant expansion and TAP theory are classic methods from non-equilibrium statistical physics. Neither is convex. Neither is exact. In fact, it is unclear if these expansions even converge, although they may be asymptotically convergent. The cumulants are very old, and applicable to general distributions. TAP theory is specific to spin glass theory, and can be applied to neural networks with some modifications.
Perturbation Theory vs Variational Inference
The cumulants play a critical role in statistical physics and quantum chemistry because they provide a size-extensive approximation. That is, in the limit of a very large deep net (
For example, mean field theories obey this scaling. Variational theories generally do not obey this scaling when they include correlations, but perturbative methods do.
Spin Glasses and Bayes Optimal Inference
The variational theorem is easily proven using jensen’s inequality, as in David Beli’s notes.
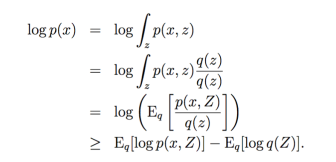
In the context of spin glass theory, for those who remember this old stuff, this means that we have expressions like
![log\;\mathbb{E}[\cdots]_{q}=\mathbb{E}_{q}[log\;(\cdots)]](https://s0.wp.com/latex.php?latex=log%5C%3B%5Cmathbb%7BE%7D%5B%5Ccdots%5D_%7Bq%7D%3D%5Cmathbb%7BE%7D_%7Bq%7D%5Blog%5C%3B%28%5Ccdots%29%5D&bg=ffffff&fg=%23000000&s=0&c=20201002)
which, for a given spin glass model, occurs at the boundary (i.e. the Nishimori line) of the spin glass phase. I will discuss this more in an further post.
Well, it has been a long post, which seems appropriate for Labor Day.
But there is more, in the
Appendix
Derivation of the RBM Free Energy derivatives
I will try to finish this soon; the derivation is found in Ali Ghodsi, Lec [7], Deep Learning , Restricted Boltzmann Machines (RBMs)
VAEs in Keras
I think it is easier to understand the Kigma and Welling paper AutoEncoding Variational Bayes by looking at the equations next to Keras Blog and code. We are minimizing the Variational Free Energy, but reformulate it using the mean field approximation and the reparameterization trick.
The mean field approximation
We choose a model Q that factorizes into Gaussians


We can also use other distributions, such as
- a soft-max Gumbel distribution to represent categorical latent variables.
- Gaussian Mixture models for Deep Unsupervised Clustering
Being mean field, the VAE model Energy function $mathcal{H}_{q}(\mathbf{x},\mathbf{z})&bg=ffffff$ is effectively an RBM-like quadratic Energy function 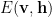
We use a factored distribution to reexpress the KL regularizer using
the re-parameterization trick
We can not backpropagate through a literal stochastic node z because we can not form the gradient. So we just replace the innermost hidden layer with a continuous latent space, and form z by sampling from this.
We reparameterize z with explicit random values 
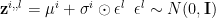
Show me the code
In Keras, we define z with a (Lambda) sampling function, eval’d on each batch step

and use this z in the last decoder hidden layer

Of course, this slows down execution since we have to call K.random_normal on every SGD batch.
We estimate mean and variance for the 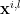
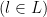
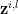

This is inserted directly into the VAE Loss function. For each a minibatch (of size L), L is

where the KL Divergence (kl_loss) is approximated in terms of the mini-batch estimates for the mean 

in Keras, the loss looks like:
 We can now apply BackProp using SGD, RMSProp, etc. to minimize the VAE Loss, with
We can now apply BackProp using SGD, RMSProp, etc. to minimize the VAE Loss, with 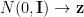
Different expressions for the Free Energy
In machine learning, we use expected value notation, such as
![-\mathcal{F}_{eq}=log\;Z_{eq}=log\;\mathbb{E}_{p((\mathbf{x},\mathbf{z})}[exp[E(\mathbf{x},\mathbf{z})]]](https://s0.wp.com/latex.php?latex=-%5Cmathcal%7BF%7D_%7Beq%7D%3Dlog%5C%3BZ_%7Beq%7D%3Dlog%5C%3B%5Cmathbb%7BE%7D_%7Bp%28%28%5Cmathbf%7Bx%7D%2C%5Cmathbf%7Bz%7D%29%7D%5Bexp%5BE%28%5Cmathbf%7Bx%7D%2C%5Cmathbf%7Bz%7D%29%5D%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
but in physics and chemistry there at 5 or 6 other notations. I jotted them down here for my own sanity.
For RBMs and other discrete objects, we have
![-\beta\mathcal{F}=ln\sum\limits_{k=0}^{N}exp[-\beta E_{k}]](https://s0.wp.com/latex.php?latex=-%5Cbeta%5Cmathcal%7BF%7D%3Dln%5Csum%5Climits_%7Bk%3D0%7D%5E%7BN%7Dexp%5B-%5Cbeta+E_%7Bk%7D%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
Of course, we may want the limit 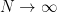
![-\beta\mathcal{F}=ln\sum\limits_{k=0}^{\infty}exp[-\beta E_{k}]](https://s0.wp.com/latex.php?latex=-%5Cbeta%5Cmathcal%7BF%7D%3Dln%5Csum%5Climits_%7Bk%3D0%7D%5E%7B%5Cinfty%7Dexp%5B-%5Cbeta+E_%7Bk%7D%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
In the continuous case, we specify a density of states $latex \rho(E)&bg=ffffff $
![-\beta\mathcal{F}=ln\int\limits_{0}^{\infty}d\rho(E)exp[-\beta E]](https://s0.wp.com/latex.php?latex=-%5Cbeta%5Cmathcal%7BF%7D%3Dln%5Cint%5Climits_%7B0%7D%5E%7B%5Cinfty%7Dd%5Crho%28E%29exp%5B-%5Cbeta+E%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
which is not the same as specifying a distribution
![-\beta\mathcal{F}=ln\int\limits_{0}^{\infty}d\mathbf{x}p(\mathbf{x})\;exp[-\beta E(\mathbf{x})]](https://s0.wp.com/latex.php?latex=-%5Cbeta%5Cmathcal%7BF%7D%3Dln%5Cint%5Climits_%7B0%7D%5E%7B%5Cinfty%7Dd%5Cmathbf%7Bx%7Dp%28%5Cmathbf%7Bx%7D%29%5C%3Bexp%5B-%5Cbeta+E%28%5Cmathbf%7Bx%7D%29%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
In quantum statistical mechanics, we replace the Energy with the Hamiltonian operator, and replace the expectation value with the Trace operation
![-\beta\mathcal{F}=ln\;Tr[\;exp[-\beta\mathcal{H}]]](https://s0.wp.com/latex.php?latex=-%5Cbeta%5Cmathcal%7BF%7D%3Dln%5C%3BTr%5B%5C%3Bexp%5B-%5Cbeta%5Cmathcal%7BH%7D%5D%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
and this is also expressed using a bra-ket notation
![-\beta\mathcal{F}=ln\langle exp[-\beta\mathcal{H}]\rangle](https://s0.wp.com/latex.php?latex=-%5Cbeta%5Cmathcal%7BF%7D%3Dln%5Clangle+exp%5B-%5Cbeta%5Cmathcal%7BH%7D%5D%5Crangle+&bg=ffffff&fg=%23000000&s=0&c=20201002)
and usually use subscripts to represent non-equilibrium states
![-\beta\mathcal{F}_{0}=ln\;Tr[\;exp[-\beta\mathcal{H}_{0}]]](https://s0.wp.com/latex.php?latex=-%5Cbeta%5Cmathcal%7BF%7D_%7B0%7D%3Dln%5C%3BTr%5B%5C%3Bexp%5B-%5Cbeta%5Cmathcal%7BH%7D_%7B0%7D%5D%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
![-\beta\mathcal{F}_{0}=ln\langle exp[-\beta\mathcal{H}(\mathbf{x})]\rangle_{0}](https://s0.wp.com/latex.php?latex=-%5Cbeta%5Cmathcal%7BF%7D_%7B0%7D%3Dln%5Clangle+exp%5B-%5Cbeta%5Cmathcal%7BH%7D%28%5Cmathbf%7Bx%7D%29%5D%5Crangle_%7B0%7D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
Raise the Posteriors


I’m curious – what does knowing the relation of free-energy to deep learning teach us? Does it teach us something about local minima? Does it teach us ways to improve existing algorithms? Does it teach us ways to invent new algorithms? Does it teach us anything about how the mind might work? Does it suggest any new applications?
Thanks.
LikeLike
Current VAEs are not very good. Better methods are needed. Cumulants are a natural way to correct this.
Of course, cumulants are not the only statistical physics tool. There are other Free Energy approximations, such as the TAP theory we used in the deterministic EMF-RBM.
LikeLike
As for the problem of local min–this has been treated with TAP theory nearly 20 years ago. This is the basis of later work by LeCun on spin glasses.
But really…
It has been known for a long time that these kinds of systems do not suffer from the problems of local minima arise in other optimization provblems. In particular, see the Orange Book on Pattern Recognition and the chapter on neural nets
https://books.google.com/books/about/Pattern_classification.html?id=YoxQAAAAMAAJ
LikeLike
Hi,
You might be interested in checking out this ICML’17 paper: https://arxiv.org/pdf/1704.08045.pdf
They have a very concise proof for the fact that most of critical points are global minimum for a class of deep neuron networks with a standard architecture.
LikeLike
This proof was started in spin glass theory over 20 years ago
LikeLike
And thanks
LikeLike
Beyond that I don’t think a simple cumulants would do better than say applying a skip connection to deal with non local correlations. Hover, for black box variational inference , we need better methods than just vanilla free energy minimization.
LikeLike
Hi, nice post!
I have a similar discussion in my blog: https://danilorezende.com/2015/12/24/approximating-free-energies/
Small observation: While vanilla VAEs are somewhat poor generative models (this is by construction, as they have a simple posterior approximator), Recurrent/Structured VAEs (e.g. (conv)DRAW) aren’t. Recurrent VAEs are as good as PixelCNN/RNVP and are amongst the state-of-the-art in generative models for which there is a standardised evaluation metric.
Let me know if you have any comments,
Cheers
LikeLike
Great observation thanks !
LikeLike
I would add that even structured variational inference can benefit from tuning. Such as using reinforcement learning to repair the problems and / or to specify structure that is not easy to represent in an RNM .
LikeLike
Your blog is quite nice, thanks for sharing.
LikeLike
Working in engineering, I am finding your blog a bit different from my normal reading. But a fascinating subject and one I am determined to understand
LikeLike
The blog is mostly physics oriented. Feel free to ask questions
LikeLike
Thanks for sharing your ideas. Unfortunately, the link to sequential VAEs is broken and thus, I cannot find the paper for your statement: “[…] are we trying to make q model p, or p model q ?”. Can you fix this or give a link to the paper?
LikeLike
I guess this got stale. I’ll have to review this post and find some more recent references thanks. On “q model p…” these are my observations..
LikeLike
Thanks for your effort. Would be eager to read about their findings. Thanks!
LikeLike
It seems the link is still broken. Would be great if anyone could find or guess the relevant paper!
LikeLiked by 1 person
LikeLiked by 1 person
Sorry IDK what happened to it…seems to be blocked…when i search on youtube I get the Stanford video
LikeLike
Oh, how strange. Thanks anyway for the great blog post!
LikeLiked by 1 person