Restricted Boltzmann Machines (RBMs) are like the H atom of Deep Learning.
They are basically a solved problem, and while of academic interest, not really used in complex modeling problems. They were, upto 10 years ago, used for pretraining deep supervised nets. Today, we can train very deep, supervised nets directly.
RBMs are the foundation of unsupervised deep learning–
an unsolved problem.
RBMs appear to outperform Variational Auto Encoders (VAEs) on simple data sets like the Omniglot set–a data set developed for one shot learning, and used in deep learning research.

RBM research continues in areas like semi-supervised learning with deep hybrid architectures, Temperature dependence, infinitely deep RBMs, etc.
Many of basic concepts of Deep Learning are found in RBMs.
Sometimes clients ask, “how is Physical Chemistry related to Deep Learning ?”
In this post, I am going to discuss a recent advanced in RBM theory based on ideas from theoretical condensed matter physics and physical chemistry,
the Extended Mean Field Restricted Boltzmann Machine: EMF_RBM
(see: Training Restricted Boltzmann Machines via the Thouless-Anderson-Palmer Free Energy )
[Along the way, we will encounter several Nobel Laureates, including the physicists David J Thouless (2016) and Philip W. Anderson (1977), and the physical chemist Lars Onsager (1968).]
RBMs are pretty simple, and easily implemented from scratch. The original EMF_RBM is in Julia; I have ported EMF_RBM to python, in the style of the scikit-learn BernoulliRBM package.
Show me the code
https://github.com/charlesmartin14/emf-rbm/blob/master/EMF_RBM_Test.ipynb
Theory
We examined RBMs in the last post on Cheap Learning: Partition Functions and RBMs. I will build upon that here, within the context of statistical mechanics.
RBMs are defined by the Energy function

To train an RBM, we minimize the log likelihood ,

the sum of the clamped and (actual) Free Energies, where

and
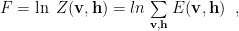
The sums range over a space of 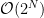
![\mathbf{v}\in[0,1]^{N_v},\mathbf{h}\in[0,1]^{N_h}](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bv%7D%5Cin%5B0%2C1%5D%5E%7BN_v%7D%2C%5Cmathbf%7Bh%7D%5Cin%5B0%2C1%5D%5E%7BN_h%7D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
which is intractable in most cases.
Training an RBM requires computing the log Free Energy; this is hard.
When training an RBM, we
- take a few ‘steps toward equilibration’, to approximate F
- take a gradient step,
, to get W, a, b
- regularize W (i.e. by weight decay)
- update W, a, b
- repeat until some stopping criteria is met
We don’t include label information, although a trained RBM can provide features for a down-stream classifier.
Extended Mean Field Theory:
The Extended Mean Field (EMF) RBM is a straightforward application of known statistical mechanics theories.
There are, literally, thousands of papers on spin glasses.
The EMF RBM is a great example of how to operationalize spin glass theory.
Mean Field Theory
The Restricted Boltzmann Machine has a very simple Energy function, which makes it very easy to factorize the partition function Z , explained by Hugo Larochelle, to obtain the conditional probabilities


The conditional probabilities let us apply Gibbs Sampling, which is simply
- hold
fixed, sample
- hold
fixed, sample
- repeat for 1 or more equlibiration steps


In statistical mechanics, this is called a mean field theory. This means that the Free Energy (in

where 
At high Temp., for a spin glass, a mean field model seems very sensible because the spins (i.e. activations) become uncorrelated.
Theoreticians use mean field models like the p-spin spherical spin glass to study deep learning because of their simplicity. Computationally, we frequently need more.
How we can go beyond mean field theory ?
The Onsager Correction

Onsager was awarded 1968 the Nobel Prize in Chemistry for the development of the Onsager Reciprocal Relations, sometimes called the ‘4th law of Thermodynamics’
The Onsager relations provides the theory to treat thermodynamic systems that are in a quasi-stationary, local equilibrium.
Onsager was the first to show how to relate the correlations in the fluctuations to the linear response. And by tying a sequence of quasi-stationary systems together, we can describe an irreversible process…
..like learning. And this is exactly what we need to train an RBM.
In an RBM, the fluctuations are variations in the hidden and visible nodes.
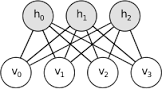
In a BernoulliRBM, the activations can be 0 or 1, so the fluctuation vectors are

The simplest correction to the mean field Free Energy, at each step in training, are the correlations in these fluctuations:
![\left[(\mathbf{h}-\mathbf{0})^{T}(\mathbf{h}-\mathbf{1})^{T}\mathbf{W}^{2} (\mathbf{v}-\mathbf{0})(\mathbf{v}-\mathbf{1})\right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%28%5Cmathbf%7Bh%7D-%5Cmathbf%7B0%7D%29%5E%7BT%7D%28%5Cmathbf%7Bh%7D-%5Cmathbf%7B1%7D%29%5E%7BT%7D%5Cmathbf%7BW%7D%5E%7B2%7D%C2%A0%28%5Cmathbf%7Bv%7D-%5Cmathbf%7B0%7D%29%28%5Cmathbf%7Bv%7D-%5Cmathbf%7B1%7D%29%5Cright%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
where W is the Energy weight matrix.
Unlike normal RBMs, here is we work in an Interaction Ensemble, so the hidden and visible units become hidden and visible magnetizations:

To simplify (or confuse?) the presentations here, I don’t write magnetizations (until the Appendix).
The corrections make sense under the stationarity constraints, that the Extended Mean Field RBM Free Energy (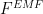
![\left[\dfrac{dF^{EMF}}{d\mathbf{v}},\dfrac{dF^{EMF}}{d\mathbf{h}}\right]=0](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cdfrac%7BdF%5E%7BEMF%7D%7D%7Bd%5Cmathbf%7Bv%7D%7D%2C%5Cdfrac%7BdF%5E%7BEMF%7D%7D%7Bd%5Cmathbf%7Bh%7D%7D%5Cright%5D%3D0+&bg=ffffff&fg=%23000000&s=0&c=20201002)
That is, small changes in the activations 
We will show that we can write
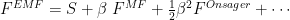
as a Taylor series in 
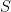
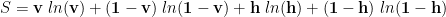


and 
![F^{Onsager}=\left[(\mathbf{h}-\mathbf{h}^{2})^{T}\mathbf{W}^{2} (\mathbf{v}-\mathbf{v}^{2})\right]](https://s0.wp.com/latex.php?latex=F%5E%7BOnsager%7D%3D%5Cleft%5B%28%5Cmathbf%7Bh%7D-%5Cmathbf%7Bh%7D%5E%7B2%7D%29%5E%7BT%7D%5Cmathbf%7BW%7D%5E%7B2%7D%C2%A0%28%5Cmathbf%7Bv%7D-%5Cmathbf%7Bv%7D%5E%7B2%7D%29%5Cright%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
Given the expressions for the Free Energy, we must now evaluate it.
Thouless-Anderson-Palmer TAP Theory
The Taylor series above is a result of the TAP theory — the Thouless-Anderson-Palmer approach developed for spin glasses.

The TAP theory is outlined in the Appendix; here it is noted that
Thouless just shared the 2016 Nobel Prize in Physics (for his work in topological phase transitions)
Temperature Dependence and Weight Decay
Being a series in inverse Temperature
Specifically, the expansion applies at Temperatures above the glass transition–a concept which I describe in a recent video blog.
Here, to implement the EMF_RBM, we set

and, instead, apply weight decay to keep the weights W from exploding
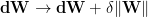
where 
Weight Decay acts to keep the Temperature high.
RBMs with explicit Temperature
Early RBM computational models were formulated using statistical mechanics (see the Appendix) language, and so included a Temperature parameter, and were solved using techniques like simulated annealing and the (mean field) TAP equations (described below).
Adding Temperature allowed the system to ‘jump’ out of the spurious local minima. So any usable model required a non-zero Temp, and/or some scheme to avoid local minima that generalized poorly. (See: Learning Deep Architectures for AI, by Bengio)
These older approaches did not work well –then — so Hinton proposed the Contrastive Divergence (CD) algorithm. Note that researchers struggled for some years to ‘explain’ what optimization problem CD actually solves.
More that recent work on Temperature Bases RBMs also suggests that higher T solutions perform better, and that
“temperature is an essential parameter controlling the selectivity of the firing neurons in the hidden layer.”
Training without Sampling: Fixed Point equations
Standard RBM training approximates the (unconstrained) Free Energy, F=ln Z, in the mean field approximation, using (one or more steps of) Gibbs Sampling. This is usually implemented as Contrastive Divergence (CD), or Persistent Contrastive Divergence (PCD).
Using techniques of statistical mechanics, however, it is possible to train an RBM directly, without sampling, by solving a set of deterministic fixed point equations.
Indeed, this approach clarifies how to view an RBM as solving a (determinisitic) fixed point equation of the form

Consider each step, at at fixed (
We can use the stationary conditions to derive a pair of coupled, non-linear equations
![v_{i}\simeq\sigma\left[a_{i}+\underset{j}{\sum}w_{i,j}h_{j}-(v_{i}-\frac{1}{2})w^{2}_{i,j}(h_{j}-(h_{j})^{2})+\cdots\right]](https://s0.wp.com/latex.php?latex=v_%7Bi%7D%5Csimeq%5Csigma%5Cleft%5Ba_%7Bi%7D%2B%5Cunderset%7Bj%7D%7B%5Csum%7Dw_%7Bi%2Cj%7Dh_%7Bj%7D-%28v_%7Bi%7D-%5Cfrac%7B1%7D%7B2%7D%29w%5E%7B2%7D_%7Bi%2Cj%7D%28h_%7Bj%7D-%28h_%7Bj%7D%29%5E%7B2%7D%29%2B%5Ccdots%5Cright%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
![h_{i}\simeq\sigma\left[b_{i}+\underset{j}{\sum}w_{i,j}v_{j}-(h_{i}-\frac{1}{2})w^{2}_{i,j}(v_{j}-(v_{j})^{2})+\cdots\right]](https://s0.wp.com/latex.php?latex=h_%7Bi%7D%5Csimeq%5Csigma%5Cleft%5Bb_%7Bi%7D%2B%5Cunderset%7Bj%7D%7B%5Csum%7Dw_%7Bi%2Cj%7Dv_%7Bj%7D-%28h_%7Bi%7D-%5Cfrac%7B1%7D%7B2%7D%29w%5E%7B2%7D_%7Bi%2Cj%7D%28v_%7Bj%7D-%28v_%7Bj%7D%29%5E%7B2%7D%29%2B%5Ccdots%5Cright%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
They extend the standard formula of sigmoid linear activations 
They differs significantly from (simple) Deep Learning activation functions because the activation for each layer explicitly includes information from other layers.
This extension couples the mean (

We can not satisfy both equations simultaneously, but we can satisfy each condition
![v_{i}[t+1]\leftarrow\sigma\left[a_{i}+\underset{j}{\sum}w_{i,j}h_{j}[t]-(v_{i}[t]-\frac{1}{2})w^{2}_{i,j}(h_{j}[t]-(h_{j}[t])^{2})\right]](https://s0.wp.com/latex.php?latex=v_%7Bi%7D%5Bt%2B1%5D%5Cleftarrow%5Csigma%5Cleft%5Ba_%7Bi%7D%2B%5Cunderset%7Bj%7D%7B%5Csum%7Dw_%7Bi%2Cj%7Dh_%7Bj%7D%5Bt%5D-%28v_%7Bi%7D%5Bt%5D-%5Cfrac%7B1%7D%7B2%7D%29w%5E%7B2%7D_%7Bi%2Cj%7D%28h_%7Bj%7D%5Bt%5D-%28h_%7Bj%7D%5Bt%5D%29%5E%7B2%7D%29%5Cright%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
![h_{i}[t+1]\leftarrow\sigma\left[b_{i}+\underset{j}{\sum}w_{i,j}v_{j}[t+1]-(h_{i}[t+1]-\frac{1}{2})w^{2}_{i,j}(v_{j}[t+1]-(v_{j}[t+1])^{2})\right]](https://s0.wp.com/latex.php?latex=h_%7Bi%7D%5Bt%2B1%5D%5Cleftarrow%5Csigma%5Cleft%5Bb_%7Bi%7D%2B%5Cunderset%7Bj%7D%7B%5Csum%7Dw_%7Bi%2Cj%7Dv_%7Bj%7D%5Bt%2B1%5D-%28h_%7Bi%7D%5Bt%2B1%5D-%5Cfrac%7B1%7D%7B2%7D%29w%5E%7B2%7D_%7Bi%2Cj%7D%28v_%7Bj%7D%5Bt%2B1%5D-%28v_%7Bj%7D%5Bt%2B1%5D%29%5E%7B2%7D%29%5Cright%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
These fixed point equations converge to the stationary solution, leading to a local equilibrium. Like Gibbs Sampling, however, we only need a few iterations (say t=3 to 5). Unlike Sampling, however, the EMF RBM is deterministic.
Implementation
- The original implementation of the EMF-RBM is in the Sphinx Team Julia package Boltzmann.jl
- I have ported the second order EMF-RBM to python, in the style of the scikit learn BernoulliRBM package. The python code is available at
https://github.com/charlesmartin14/emf-rbm/
If there is enough interest, I can do a pull request on sklearn to include it.
The next blog post will demonstrate how the python code in action.
Appendix
the Statistical Mechanics of Inference
Early work on Hopfield Associative Memories
Most older physicists will remember the Hopfield model. They peaked in 1986, although interesting work continued into the late 90s (when I was a post doc).
Originally, Boltzmann machines were introduced as a way to avoid spurious local minima while including ‘hidden’ features into Hopfield Associative Memories (HAM).
Hopfield himself was a theoretical chemist, and his simple model HAMs were of great interest to theoretical chemists and physicists.
Hinton explains Hopfield nets in his on-line lectures on Deep Learning.
The Hopfield Model is a kind of spin glass, which acts like a ‘memory’ that can recognize ‘stored patterns’. It was originally developed as a quasi-stationary solution of more complex, dynamical models of neuronal firing patterns (see the Cowan-Wilson model).
Early theoretical work on HAMs studied analytic approximations to ln Z to compute their capacity (
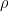

The Hopfield model was traditionally run at T=0.
Looking at the T=0 line, at extremely low capacity, the system has stable mixed states that correspond to ‘frozen’ memories. But this is very low capacity, and generally unusable. Also, when the capacity too large, 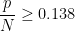
There is a small window of capacity, 
So the Hopfield model suggested that
glass states can be useful minima, but
we want to avoid low energy (spurious) glassy states.
One can try to derive direct mapping between Hopfield Nets and RBMs (under reasonable assumptions). Then the RBM capacity is proportional to the number of Hidden nodes. After that, the analogies stop.
The intuition about RBMs is different since (effectively) they operate at a non-zero Temperature. Additionally, it is unclear to this blogger if the proper description of deep learning is a mean field spin glass, with many useful local minima, or a strongly correlated system, which may behave very differently, and more like a funneled energy landscape.
Thouless-Anderson-Palmer Theory of Spin Glasses
The TAP theory is one of the classic analytic tools used to study spin glasses and even the Hopfield Model.
We will derive the EMF RBM method following the Thouless-Anderson-Palmer (TAP) approach to spin glasses.
On a side note he TAP method introduces us to 2 more Nobel Laureates:
- David J Thouless, 2016 Nobel Prize in Physics
- Phillip W Anderson, 1977 Nobel Prize in Physics
The TAP theory, published in 1977, presented a formal approach to study the thermodynamics of mean field spin glasses. In particular, the TAP theory provides an expression for the average spin
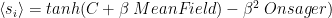
where 
In 1977, they argued that the TAP approach would hold for all Temperatures (and external fields), although it was only proven until 25 years later by Talagrand. It is these relatively new, rigorous approaches that are cited by Deep Learning researchers like LeCun , Chaudhari, etc. But many of the cited results have been suggested using the TAP approach. In particular, the structure of the Energy Landscape, has been understood looking at the stationary points of the TAP free energy.
More importantly, the TAP approach can be operationalized, as a new RBM solver.
The TAP Equations
We start with the RBM Free Energy 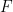
Introduce an ‘external field’ 
![\beta F[\mathbf{q}]=\ln\;\sum\limits_{\mathbf{s}}\exp(-\beta[ E(\mathbf{s})-\mathbf{q}^{T}\mathbf{s}])](https://s0.wp.com/latex.php?latex=%5Cbeta+F%5B%5Cmathbf%7Bq%7D%5D%3D%5Cln%5C%3B%5Csum%5Climits_%7B%5Cmathbf%7Bs%7D%7D%5Cexp%28-%5Cbeta%5B+E%28%5Cmathbf%7Bs%7D%29-%5Cmathbf%7Bq%7D%5E%7BT%7D%5Cmathbf%7Bs%7D%5D%29+&bg=ffffff&fg=%23000000&s=0&c=20201002)
Physically, 
As is standard in statistical mechanics, we take the Legendre Transform, in terms of a set of conjugate variables 
![-\beta\;\Gamma[\mathbf{m}]=-\beta\;\underset{\mathbf{q}}{\max}\left[F[\mathbf{q}]+\mathbf{m}^{T}\mathbf{q}\right]](https://s0.wp.com/latex.php?latex=-%5Cbeta%5C%3B%5CGamma%5B%5Cmathbf%7Bm%7D%5D%3D-%5Cbeta%5C%3B%5Cunderset%7B%5Cmathbf%7Bq%7D%7D%7B%5Cmax%7D%5Cleft%5BF%5B%5Cmathbf%7Bq%7D%5D%2B%5Cmathbf%7Bm%7D%5E%7BT%7D%5Cmathbf%7Bq%7D%5Cright%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
The transform which effectively defines a new interaction ensemble ![\Gamma[\mathbf{m}]](https://s0.wp.com/latex.php?latex=%5CGamma%5B%5Cmathbf%7Bm%7D%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
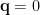
![-\beta F=\beta\;F[\mathbf{q}=0]=\beta\;\underset{\mathbf{q}}{\min}\left[\Gamma[\mathbf{m}]\right]=-\beta\;\Gamma[\mathbf{m}^{*}]](https://s0.wp.com/latex.php?latex=-%5Cbeta+F%3D%5Cbeta%5C%3BF%5B%5Cmathbf%7Bq%7D%3D0%5D%3D%5Cbeta%5C%3B%5Cunderset%7B%5Cmathbf%7Bq%7D%7D%7B%5Cmin%7D%5Cleft%5B%5CGamma%5B%5Cmathbf%7Bm%7D%5D%5Cright%5D%3D-%5Cbeta%5C%3B%5CGamma%5B%5Cmathbf%7Bm%7D%5E%7B%2A%7D%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
Define an interaction Free Energy to describe the interaction ensemble
![A(\beta,\mathbf{m})=\beta\;\Gamma[\mathbf{m}]](https://s0.wp.com/latex.php?latex=A%28%5Cbeta%2C%5Cmathbf%7Bm%7D%29%3D%5Cbeta%5C%3B%5CGamma%5B%5Cmathbf%7Bm%7D%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
which equals the original Free Energy when
Note that because we have visible and hidden spins (or nodes), we will identify magnetizations for each
![\mathbf{m}=[\mathbf{m^{v},m^{h}}]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bm%7D%3D%5B%5Cmathbf%7Bm%5E%7Bv%7D%2Cm%5E%7Bh%7D%7D%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
Now, recall we want to avoid the glassy phase; this means we keep the Temperature high. Or
We form a low Taylor series expansion
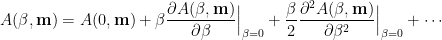
which, at low order in
This leads to an order-by-order expansion for the Free Energy 


Second Order Free Energy
Upto 



or

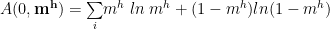

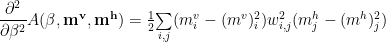
Stationary Condition
Rather than assume equilibrium, we assume that, at each step during inference –at fixed (
![\dfrac{dA}{d\mathbf{m}}=\left[\dfrac{dA}{d\mathbf{m^{v}}},\dfrac{dA}{d\mathbf{m^{h}}}\right]=0](https://s0.wp.com/latex.php?latex=%5Cdfrac%7BdA%7D%7Bd%5Cmathbf%7Bm%7D%7D%3D%5Cleft%5B%5Cdfrac%7BdA%7D%7Bd%5Cmathbf%7Bm%5E%7Bv%7D%7D%7D%2C%5Cdfrac%7BdA%7D%7Bd%5Cmathbf%7Bm%5E%7Bh%7D%7D%7D%5Cright%5D%3D0+&bg=ffffff&fg=%23000000&s=0&c=20201002)
Stationary Magnetizations
Applying the stationary conditions lets us write coupled equations for the individual magnetizations that effectively define the (second order), high Temp, quasi-equilibrium states
![m^{v}_{i}\simeq\sigma\left[a_{i}+\underset{j}{\sum}w_{i,j}m^{h}_{j}-(m^{v}_{i}-\frac{1}{2})w^{2}_{i,j}(m^{h}_{j}-(m^{h}_{j})^{2})\right]](https://s0.wp.com/latex.php?latex=m%5E%7Bv%7D_%7Bi%7D%5Csimeq%5Csigma%5Cleft%5Ba_%7Bi%7D%2B%5Cunderset%7Bj%7D%7B%5Csum%7Dw_%7Bi%2Cj%7Dm%5E%7Bh%7D_%7Bj%7D-%28m%5E%7Bv%7D_%7Bi%7D-%5Cfrac%7B1%7D%7B2%7D%29w%5E%7B2%7D_%7Bi%2Cj%7D%28m%5E%7Bh%7D_%7Bj%7D-%28m%5E%7Bh%7D_%7Bj%7D%29%5E%7B2%7D%29%5Cright%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
![m^{h}_{i}\simeq\sigma\left[b_{i}+\underset{j}{\sum}w_{i,j}m^{v}_{j}-(m^{h}_{i}-\frac{1}{2})w^{2}_{i,j}(m^{v}_{j}-(m^{v}_{j})^{2})\right]](https://s0.wp.com/latex.php?latex=m%5E%7Bh%7D_%7Bi%7D%5Csimeq%5Csigma%5Cleft%5Bb_%7Bi%7D%2B%5Cunderset%7Bj%7D%7B%5Csum%7Dw_%7Bi%2Cj%7Dm%5E%7Bv%7D_%7Bj%7D-%28m%5E%7Bh%7D_%7Bi%7D-%5Cfrac%7B1%7D%7B2%7D%29w%5E%7B2%7D_%7Bi%2Cj%7D%28m%5E%7Bv%7D_%7Bj%7D-%28m%5E%7Bv%7D_%7Bj%7D%29%5E%7B2%7D%29%5Cright%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
Notice that the 
Mean Field Theory



And in the late 90’s, mean field TAP theory was attempted, unsuccessfully, to create an RBM solver.
Fixed Point Equations
At second order, the magnetizations
Higher Order Corrections
We can include higher order correction the Free Energy 

Plefka derived these terms in 1982, although it appears he only published up to the Onsager correction; a recent paper shows how to obtain all high order terms.
The Diagrammatic expansion appears not to have been fully worked out, and is only sketched above.
I can think of at least 3 ways to include these higher terms:
- Include all terms at a higher order in
. This changes both the Free Energy and the associated fixed point equations for the magnetizations.


- Resum all diagrams of a certain kind. This is an old-school renormalization procedure, and it would include an
number of terms. This requires working out the analytic expressions for some class of diagrams, such as all circle (RPA-like) diagrams

all circle diagrams This is similar, in some sense, to the infinite RBM by Larochelle, which uses an resummation trick to include an infinite number of Hidden nodes.
- Use a low order Pade Approximant, to improve the Taylor Series. The idea is to include higher order terms implicitly by expanding the Free Energy as a ratio of polynomial functions P, Q


Obviously there are lots of interesting things to try.
Beyond Binary Spins; Real-Valued RBMs
The current python EMF_RBM only treats binary data, just like the scikit learn BernoulliRBM. So for say MNIST, we have to use the binarized MNIST.
There is some advantage to using Binarized Neural Networks on GPUs.
Still, a non-binary RBM may be useful. Tremel et. al. have suggested how to use real-valued data in the EMF_RBM, although in the context of Compressed Sensing Using Generalized Boltzmann Machines.

Very interesting!
But, I am still stuck trying to understand the role of temperature, and its connection to the energy landscapes.
These are some of my confusions:
You talk about the spin-glass phase as being very rugged and without a very clear global minimum (like at 42:00 ). But then you talk about it as having a golf-hole-like landscape. Which one is the correct one?
I don’t still quite get the connection between the weight constraints and the temperature. Can you point me to some resources that could make me understand it better?
Why does avoiding the spin-glass state help avoid overfitting? I thought that overfitting tended to correspond to the global minimum, or some minimum close to it. The funneled landscape seems to help in falling into it. I suppose maybe you fall into one of the nearby minima, and those aren’t actually overfitting, and you are very unlikely to fall into the actual global minimum which does overfit? I’m not too clear about this.. Also, how would being being in the glassy state correspond to overfitting? Wouldn’t you just get stuck in some random local minimum?
I hope you are able to clarify these conceptual points, as I really want to get this!
LikeLike
No one knows how to characterize the energy landscape of a deep learning system. It’s not even clear how to distinguish between entropic and energetic effects in many nets. Here, I am explaining that we can get away with a high temperature expansion, and we avoid possible glassy states by keeping weights from exploding. On references — the Hopfield model is very well understood and I can provide a reference . On spin glasses, there are thousands of papers on spin glasses. I try here to show something that is operationally useful and theoretically sound.
LikeLike
Thanks for the reply!
As far as I understand, the issue with spin-glass phases is that there are lots of sharp local minima, and your neural network will get stuck in one, and not get a chance to approach a good minimum. But this isn’t overtraining right? I thought overtraining was more about finding the global minimum (which i guess is at the end of the funnel) that has too low training error..
Also you say the spin glass state is at low temperature for the Hopfield network, but in your picture: https://charlesmartin14.files.wordpress.com/2016/10/g35.gif?w=316&h=185 at low temperature you have the ferromagnetic phase, while the spin glass is above it, and to the right, right? In the work on temperature-dependent RBMs (https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4725829/ ), however, they do find the network has bad performance at too low temperatures, in a way that seems glassy to me.
In any case, at least I agree and I think I understand why glassy states are bad.., I just don’t see why they correspond to overfitting.
LikeLike
There is no good theory which explains how the energy landscape corresponds to overfitting. This is not the best blog to discuss this–I would prefer the comments on the earlier page so we can reference specific sections in the video. Still, I can address some of there here. In the standard picture, yes, it is assumed that 1. there is a ground state corresponds to a state and 2. that this corresponds to over training. So why is this idea pushed on us ? First, it is based on operational experience that the same network can be trained with multiple random inputs, and, yet the final results are all of equal quality. This suggests that there are a large number of degenerate local minima. Second, it is observed that training schemes need early stopping, otherwise the system collapses of overtrains. So it is assumed that without early stopping, the system ends up in a ground state , that is overtrained. This is the standard ‘picture’. Now this may or may not be a good model for what is going on. I do not specifically oppose this; I am simply stating that the evidence is very sketchy, and the picture is incomplete. In contrast, the Hopfield model is very well understood — and the glassy states definately correspond to states of confusion. In the picture the glassy states arise when the capacity is too high. (Ill explain the picture in the next comment) My point here is to make this analogy and get some discussion.
I will stop here and let you comment on the video specifically so I can address the specific issues 1 by 1. Here, stil, in all of this, you will notice that there is no discussion of temperature — the energy scale. But it is essential to discuss the energy scale when discussing spin glasses and associated models, since the energy landscape changes significantly with temperature. In ML terminology, one would say that the ‘concentration limits’ are different at different energy scales. Instead, the issue of scale is buried in the notion of ‘weight regularization’. Now if we just think for a few minutes we will realize that weight regularization is a proxy for temperature control; after all, in the canonical ensemble, the temperature is just the fluctuations in the energy. So when we control fluctuations in the weights (via weight decay, batch norm regularization, etc), we are, in effect, controlling the temperature. This is so obvious to the authors of the EMF RBM paper that they just comment on it briefly. It is, however, a critical piece of their argument, so I highlight it in more detail in the blog to get people thinking about it.
LikeLike
On the hopfield phase diagram, perhaps I was a bit loose in using this. It is a reasonable question.And I think what is confusing is that the Hopfield model is usually run at zero Temp, so the only thermodynamic variable is the capacity. Still, I’ll describe what is going on There are 4 phases depicted. The very high T phases corresponds to a trivial solution, of no interest. The “stable mixed states” and “stable pattern equilibria” correspond to ‘retrieval states’ and spin glass states. Both phases have good retrieval states and spurious spin glass states. In the lower T , “stable mixed states” phase, the desired states are the global minima. In the higher T , “stable pattern equilibria”, the stable states are spin glass states. In the “low energy spin glass states”, all the states are glassy and of no interest. so what happens is at very low T, the ground state is present, a kind of frozen system, with very low capacity. The typical picture is to increase capacity, the system becomes glassy, and has no frozen global minima.
LikeLike
The free energy function being minimized for an RBM had both an entropy and an energy component. I did not understand what ‘entropy’ meant in this context. Does it mean “disorder” is minimized? “information” is maximized? And if so, what disorder, or what information? With energy as well, did it mean that incompatibilities (such as incompatible spins in a spin glass) are minimized? If so, what incompatibilities?
And I didn’t quite understand why having vast number of hidden units makes for a more convex energy landscape. Does it have something to do with ‘degrees of freedom’ or with more ways existing of reaching a solution?
Could you suggest topics that I should read before reading your blog – perhaps statistical mechanics or other topics?
LikeLike
The RBM is a mathematical construct from right out of classical statistical mechanics. Of course, it would be, since Geoff Hinton studied under Christopher Longuet Higgins, a very famous theoretical chemist.
Entropy is a fundamental concept from physical chemistry, ala Gibbs. Shannon Information theory came later. The classic work on this is by Jaynes, although you can read my blog
https://charlesmartin14.wordpress.com/2013/11/14/metric-learning-some-quantum-statistical-mechanics/
Entropy is also fundamental to VC theory, where it is related to the effective volume of the Hilbert space carved out by an (infinite dimensional) Kernel subject to regularization.
The convexity issue is more complicated, and my own idea. This comes from the Energy Landscape Theory of Protein Folding
see: https://charlesmartin14.wordpress.com/2015/03/25/why-does-deep-learning-work/
(or https://charlesmartin14.wordpress.com/2015/03/25/why-does-deep-learning-work/)
In Energy Landscape Theory (ELT), there is a tradeoff between Entropy and Energy. In classical ML , Entropy is controlled by regularizer. The Loss function is basically fixed to the data and the labels. In ELT, the Loss (Energy) and Entropy are both changing, and for convexity to arise, the Energy continues to be minimized even though the Entropy has stabilized. This means, in a Deep Learning system, we are not simply controlling the capacity of the learner, but also optimizing the Loss function on the data.
LikeLike