Double Descent (DD) is something that has surprised statisticians, computer scientists, and deep learning practitioners–but it was known in the physics literature in the 80s: And while DD can seem complicated in deep learning models, the original model is actually very easy to understand — and reproduce — with just a few lines of python.
IMHO, DD is a great way to understand how and when Deep Neural Networks might overfit their data, and, moreover, where they achieve optimal performance. And you can do this and more with the open-source weightwatcher tool
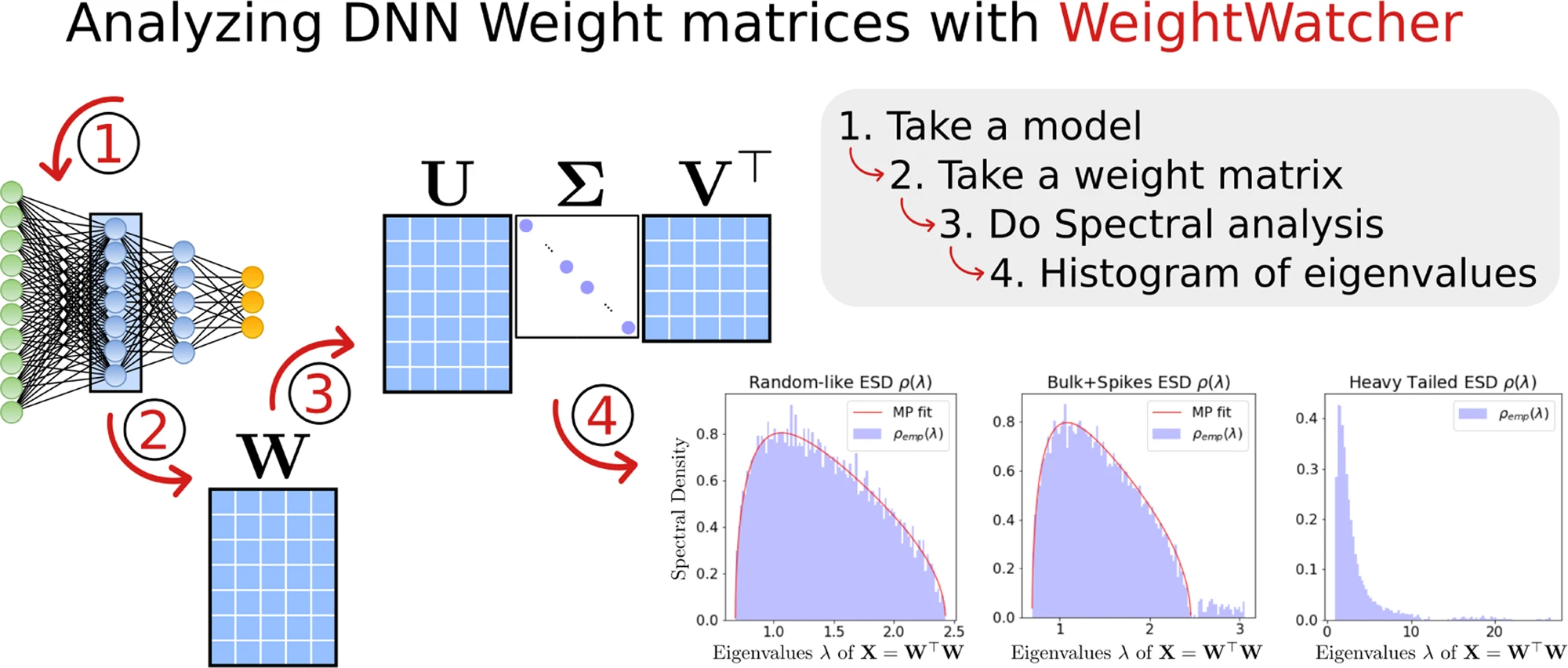
The original 1989 DD physics experiment
The original DD experiment from 1989 is easy to set up and run using modern python.
Here’s a notebook that you can run on Google Colab to reproduce all these results, and with a lot more details. (a lot)
Note: Sorry github won’t display this notebook, but it works fine. IDK why. You can also access the notebook on google colab here.
One simply trains a Linear Regression to predict the labels of a dataset with binary labels.
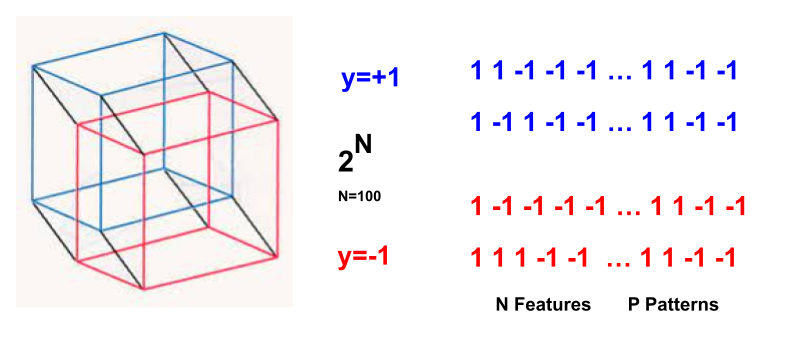
In this case, the data instances are drawn from the vertices of an N-dimensional hypercube and the labels are +1 or -1, depending on the sum of the ‘1s’ in the instance data vector.
This gives the linear equation
![\mathbf{x}^{T}\mathbf{w} = y \in [+1 |-1]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bx%7D%5E%7BT%7D%5Cmathbf%7Bw%7D+%3D+y+%5Cin+%5B%2B1+%7C-1%5D&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
where each data vector (x), label (y=[-1|1]), and weight vector (w). Of course, the goal is to learn the N-dimension weight vector (w) given P training data instances.
We can generate the data vectors (x) and their labels (y) using this code (from the notebook):
def generate_mdp_dataset_numpy(P, N):
X = np.random.choice([-1, 1], size=(P, N))
Y = generate_majority_labels(X)
return X, Y
Lets run the experiment 100 times and plot the aveage results. Lets pick 

![\alpha\in[0,2]](https://s0.wp.com/latex.php?latex=%5Calpha%5Cin%5B0%2C2%5D&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
To just get the resuilts, we can use the scikit-learn LinearRegression module. Again, we run Linear (not Logistic) Regression to predict the binary labels ![y\in[+1|-1].](https://s0.wp.com/latex.php?latex=y%5Cin%5B%2B1%7C-1%5D.&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
def run_LR_experiment(alpha=1.0, verbose=True, N=100):
P = int(alpha * N)
X_train, Y_train = generate_mdp_dataset_numpy(P,N)
X_test, Y_test = generate_mdp_dataset_numpy(P,N)
# Train the linear regression model
regressor = LinearRegression(fit_intercept=False)
regressor.fit(X_train, Y_train)
# Predict Y values for the training and test sets
Y_train_value = regressor.predict(X_train)
Y_test_value = regressor.predict(X_test)
# Convert predictions to binary class labels based on the condition
Y_train_pred = np.where(Y_train_value > 0, 1, -1) # Converts to 1 if Y > 0 else -1
Y_test_pred = np.where(Y_test_value > 0, 1, -1) # Converts to 1 if Y > 0 else -1
# Compute accuracy for both training and test sets
train_accuracy = accuracy_score(Y_train, Y_train_pred)
test_accuracy = accuracy_score(Y_test, Y_test_pred)
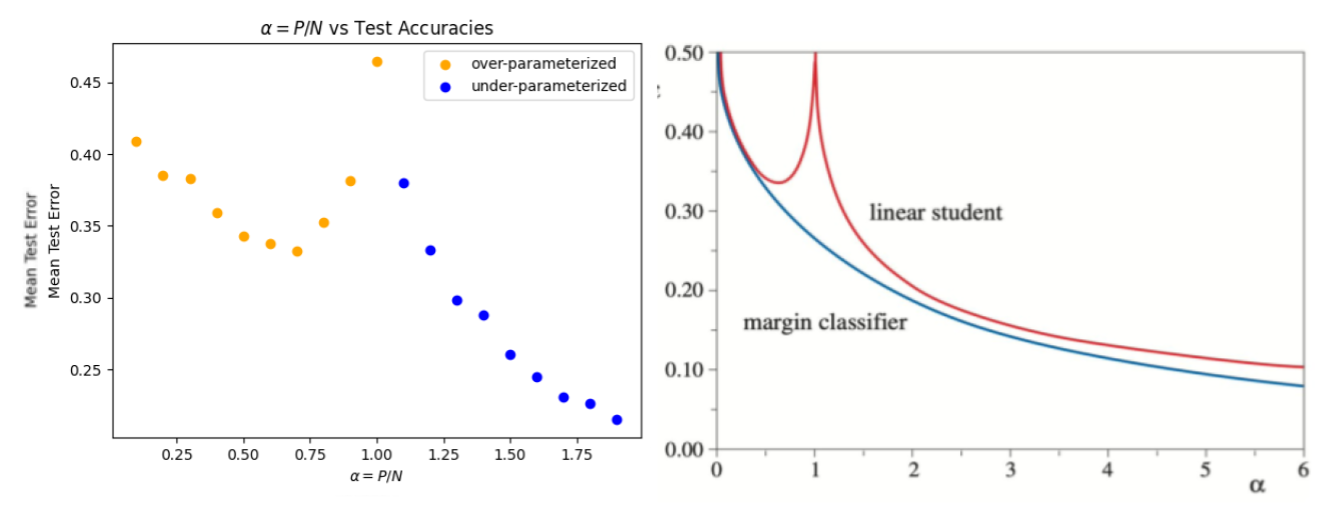
Doing this, we can reproduce the the original DD curve. On the LHS, I reproduced the experiment from the 1989 paper that discovered it . On the RHS, I present theoretical curves (from Opper 1995; ask me for a copy) using both statistical mechanics (StatMech, red) and statistical learning theory (SLT, blue). Notice that it is the StatMech approach that matches experiment. But we don’t need StatMech to understand this…
- N: Number of features / parameters
- P: Number of training examples (i.e Patterns)
- alpha: the ‘load’ parameter (note: this is not the weightwatcher alpha)
There are 2 regimes of interest”:
- under-parameterized: P > N. We have more training data than features. Here, we can always make the model better by just adding more data. Way more data. That’s easy.
- over-parameterized: N > P: We have more features, and therefore more adjustable weights, than training data. Of course, in this simple model, the test accuracy is no better than say 65%. But it does work. And this is the regime most interesting to LLMs and other Deep Neural Networks.
The over-parameterized regime
When 
The traditional stats approach fails to describe the case 
Moreover, when 
The PseudoInverse solution
Given a data pair 
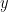
![[1|-1]](https://s0.wp.com/latex.php?latex=%5B1%7C-1%5D&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
![\mathbf{w^{T}x}=y=[1|-1]](https://s0.wp.com/latex.php?latex=%5Cmathbf%7Bw%5E%7BT%7Dx%7D%3Dy%3D%5B1%7C-1%5D&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
We want to find the weight vector 


,We can write the solutions in terms of the Moore-Penrose PseudoInverse. First, lets flip things around a little

Now, multiply by 

We now invert the data covariance matrix

We now identify the Moore-Penrose PseudoInverse operator


The optimal weight vector is given by

As part of our initial analysis, we will compute the eigenvalues 


as well as the distribution 

The weightwatcher layer quality metric (alpha)
To apply weightwatcher to the PseudoInverse problem, we need to first place the data matrix 
model = SingleLayerModel(weights=X_train)
watcher = ww.WeightWatcher(model=model)
details = watcher.analyze(inverse=True, plot=True, detX=True)
We can now plot the test accuracy as a function of the weightwatcher layer Power Law (PL) quality metric alpha 
From the left side plot, we immediately see that when
- WW PL-alpha =- 2.0, test error is minimized
- WW-PL-alpha = 1.5. test error is maximized, and the model is severely overfit
- WW PL-alpha > 2.0, test error is sub-optimal as well
Ideal Learning
On the RHS, we drill into the case where 

The weightwatcher 
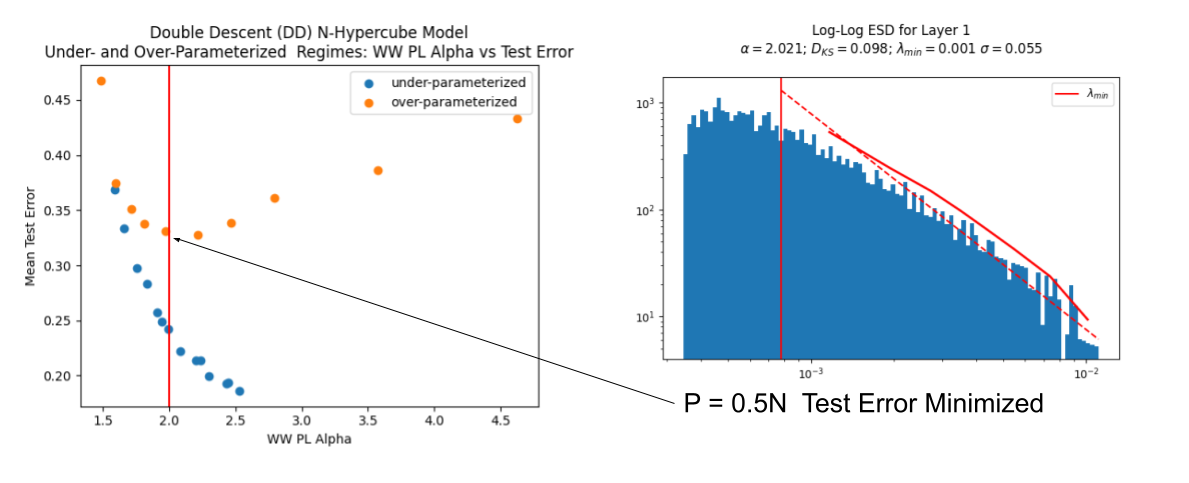
The WeightWatcher Volume Preserving Transformation
In addition to the Power Law (OK) metric alpha $\alpha_{PL}$, the weightwatcher StatMech theory (discussed in some detail at NeurIPS2023), also states that when the layer is perfectly converged for its data, then the PL tail will form an Effective Correlation Space that satisfies a Volume-Preserving Transformation.
You can check this yourself by adding the detX=True option to the analyze method
details = watcher.analyze(inverse=True, plot=True, detX=True)
and examining the plot on the lower RHS. You can tell your layer is well-trained when the red and purple lines are very close together:
Remarkably, in the case $P=0.5N$, where the test error is minimized, not only is the weightwatcher PL $\alpha_{PL}-2.0$, but the PL tail also satisfies the theoretically predicted volume preserving transformation!
But more importantly, you can use this additional weightwatcher metric to check the quality of your NN layer to see if it is properly converged, or if the layer is is overfit.
Signatures of over-fitting
When the weightwatcher 

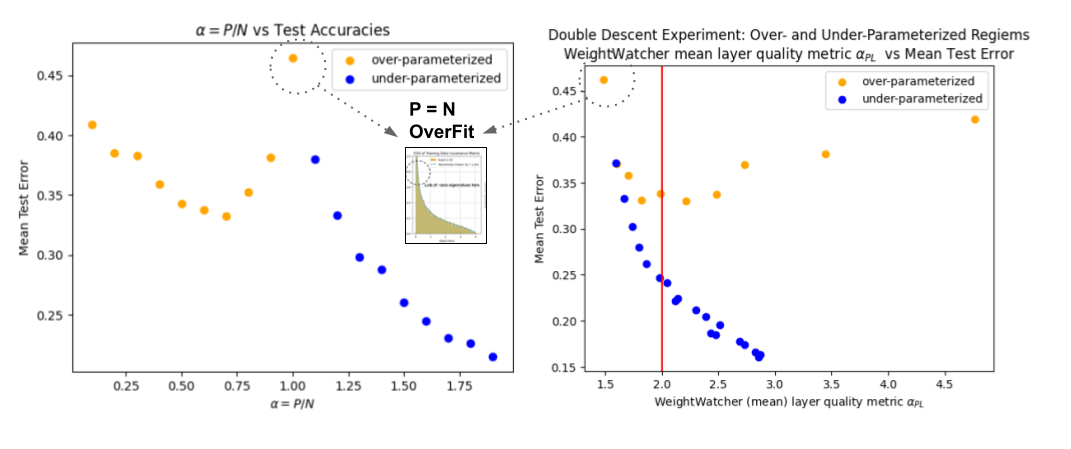
The weightwatcher theory describes the DD curve as predicted
(in the small alpha, overparameterized regime).
Now this is not explained in the old JMLR paper, but I do discuss it at some length in my recent invited talk at NeurIPS2023 (rerecorded). Also see the NeurIPS page for our Workshop on Heavy Tails ML. (with both my original talk and several others)
Why does weightwatcher work so well here. It turns out, for the case 
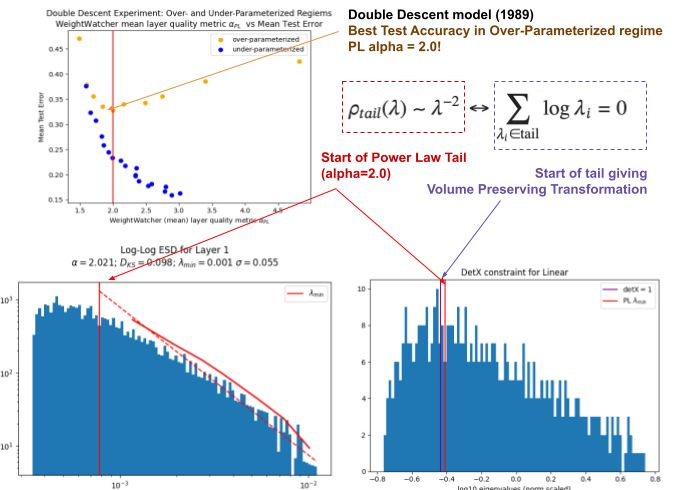
As shown on the LHS below, the ESD has many zero and near-zero eigenvalues $latex \lambda \approx 0$, which was conjectured (back in 1989) to prevent the model from describing out-ot-sample examples.
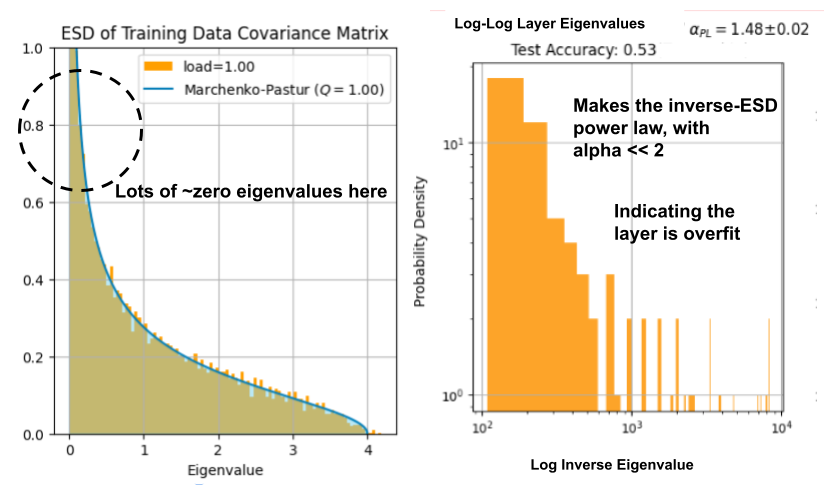
As shown on the RHS (above), when we compute the ESD of the inverse covariance matrix 
Also, as shown above, if you add the detX=True option, you can verify that your layer is overfit if the purple line is to the right of the red line. We will discuss this in detail in a future post.
The weightwatcher alpha and the HTSR theory
How are these results related to the basis of weightwatcher–from our JMLR paper on the theory of Heavy Tailed Self-Regularization?
The HTSR theory is a phenomenology that classifies a NN layer weight matrix into a specific Universality Class from Random Matrix Theory (RMT), based on the weightwatcher fit of the Power Law exponent
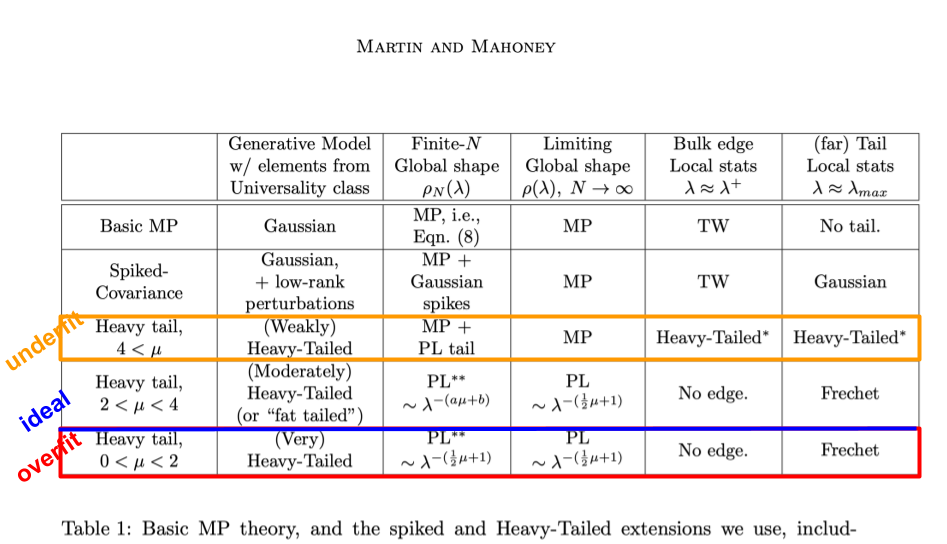
As explained in the paper, when the PL exponent of the ESD is ![\alpha_{PL}\in[2,6]](https://s0.wp.com/latex.php?latex=%5Calpha_%7BPL%7D%5Cin%5B2%2C6%5D&bg=%23ffffff&fg=%23000000&s=0&c=20201002)


Applying weightwatcher to real-world LLMs and DNNs
What can do with weightwatcher ? Ask yourself…
- Do you really know if you using enough data to fine-tune your LLM ?
- Are you worried that you are overfitting the model to your training data
- Are you having trouble evaluating your LLM ?
You can use the tool to find and fix these kinds of problems in your LLMs and NNs that no other tool can diagnose or discover.
WeightWatcher is a one-of-a-kind must-have tool for anyone training, deploying, or monitoring Deep Neural Networks (DNNs).
Learning is an inverse problem. And weightwatcher provides a view into the correlations in the training data, akin to looking at the inverse correlation matrix at different levels of granulairty. And it works even if your data is not random (like this simple model), but correlated, as in a real world problem.
You can use weightwatchet to look for potential signatures of overfitting 
You just need to ‘watch’ the model weights.

I developed weightwatcher to help my clients who are training and fine-tuning their own LLMs (and DNN AI models). If it’s useful to you, I’d love to hear about it. And it you need help training or fine-tuning your own models, please reach out. My hashtags are: #talkToChuck #theAIguy.
In the meantime, remember–Statistical Learning Theory (SLT) cannot describe Double Descent in the over-parameterized regime–but StatMech can. And so can weightwatcher!

Thanks to my friend Patrick Tangphao for this meme (haha)
