Introduction
For the past few years, we have talked a lot about how we can understand the properties of Deep Neural Networks by examining the spectral properties of the layer weight matrices 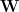

and compute the eigenvalues
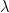

By plotting the histogram of the eigenvalues (i.e the spectral density 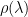
5+1 Phases of Training

Each of these phases roughly corresponds to a Universality class from Random matrix Theory (RMT). And as we shall see below, we can use RMT to develop a new theory of learning.
First, however, we note that for nearly every pretrained DNNs we have examined (and we have examined thousands of them), the phase appears to be in somewhere between Bulk-Decay and/or Heavy-Tailed .
Heavy Tailed Implicit Regularization
Moreover, for nearly all layers in all well trained, production quality DNNs, the layer spectral density

![\text{where}\;\; \alpha\in[2,4] ,\;\;\lambda_{max}<100](https://s0.wp.com/latex.php?latex=%5Ctext%7Bwhere%7D%5C%3B%5C%3B+%5Calpha%5Cin%5B2%2C4%5D+%2C%5C%3B%5C%3B%5Clambda_%7Bmax%7D%3C100+++&bg=ffffff&fg=%23000000&s=0&c=20201002)
Most importantly, in 80-90% of the DNN architectures studied, on average, smaller exponents 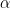
DNN Quality Metrics in Practice
Our empirical results suggest that the power law exponent can be used as (part of) a practical quality metric. This led us to propose the 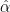

where we compute the exponent 


WeightWatcher
We have even built a open source, python command line tool–weightwatcher–so that other researchers can both reproduce and leverage our results
pip install weightwatcher
And we have a Slack Channel for those who want to ask questions, dig deeper, and/or contribute to the work. Email me, or ping me on LinkedIn, to join our vibrant group.
All of this leads to a very basic question:
Why does this work ?
To answer this, we will go back to the foundations of the theory of learning, from the physics perspective, and rebuild the theory using in both our experimental observations, some older results from Theoretical Physics, and (fairly) recent results in Random Matrix Theory.
Statistical Mechanics of Learning
Here, I am going to sketch out the ideas we are currently researching to develop a new theory of generalization for Deep Neural Networks. We have a lot of work to do, but I think we have made enough progress to present these ideas, informally, to flush out the basics.
What do we seek ? A practical theory that can be used to predict the generalization accuracy of a DNN solely by looking at the trained weight matrices, without looking at the test data.
Why ? Do you test a bridge by driving cars over it until it collapses ? Of course not! So why do we build DNNs and only rely on brute force testing ? Surely we can do better.
What is the approach ? We start with the classic Perceptron Student-Teacher model from Statistical Mechanics of the 1990s. The setup is similar, but the motivations are a bit different. We have discussed this model earlier here Remembering Generalization in DNNs. from our paper Understanding Deep Learning Requires Rethinking Generalization.
Here, let us review the mathematical setup in some detail:
the Student-Teacher model
We start with the simple model presented in chapter 2, Engel and Van der Brock, interpreted in a modern context. See also this classic 1992 paper, Statistical Mechanics of Learning from Examples.
Here, we want to do something a little different, and use the formalism of Statistical Mechanics to both compute the average generalization error, and to interpret the global convergence properties of DNNs in light of this , giving us more insight into and to provide a new theory of Why Deep Learning Works (as proposed in 2015).
Suppose we have some trained or pretrained DNN (i.e. like VGG19). We want to compute the average or typical error that our Teacher DNN could make, just by examining the layer weight matrices. Without peeking at the data.
A Simple Layer Approach: We assume all layers are statistically independent, so that the average generalization quality 
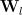
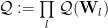
Example: The Product Norm is a Capacity (or Quality) measure for DNNs from traditional ML theory.
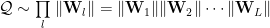
The Norm may be Frobenius Norm, the Spectral Norm, or even their ratio, the Stable Rank.
This independence assumption is probably not a great approximation but it gets us closer to a realistic theory. Indeed, even traditional ML theory recognizes this, and may use Path Norm to correct for this. For now, this will suffice.
A Log Product Norm If we take the logarithm of each side, we can write the log Quality as the sum of the layer contributions. More generally, we will express the log Quality as a weighted average of some (as yet unspecified) log norm of the weight matrix.

Quality for a Single Layer: Perceptron model
We now set up the classic Student-Teacher model for a Perceptron–with a slight twist. That is, from now on, we assume our models have 1 layer, like a Perceptron.
Let’s call our trained or pretrained DNN the Teacher T. The Teacher maps data to labels. Of course, there could be many Teachers which map the same data to the same labels. For our specific purposes here, we just fix the Teacher T. We imagine that the learning process is for us to learn all possible Student Perceptrons J that also map the data to the labels, in the same way as the Teacher.
But for a pretrained model, we have no data, and we have no labels. And that’s ok. Following Engle and Van der Brock (and also Engle’s 2001 paper ), consider the following Figure, which depicts the vector space representations of T and J.

To compute the average generalization error for a given model, we write first need the Student-Teacher (ST) error function 
![\epsilon(R)=\langle\frac{1}{2}[y_{S}-y_{T}]^{2}\rangle_{data}](https://s0.wp.com/latex.php?latex=%5Cepsilon%28R%29%3D%5Clangle%5Cfrac%7B1%7D%7B2%7D%5By_%7BS%7D-y_%7BT%7D%5D%5E%7B2%7D%5Crangle_%7Bdata%7D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
where 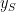

For a Linear Perceptron, the labels are given by


and the ST error function can be written in the large-N approximation, and at high-Temperature, as simply 1 minus the ST overlap

The generalization error is then simply the Thermal average of this error, written as
![\mathcal{E}_{gen}^{ST}:=\langle \epsilon(R) \rangle_{\mathbf{s}}^{\beta}=\dfrac{1}{Z}\int d\mu(\mathbf{s})\epsilon(R)\exp[-N\beta \epsilon(R)]](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BE%7D_%7Bgen%7D%5E%7BST%7D%3A%3D%5Clangle+%5Cepsilon%28R%29+%5Crangle_%7B%5Cmathbf%7Bs%7D%7D%5E%7B%5Cbeta%7D%3D%5Cdfrac%7B1%7D%7BZ%7D%5Cint+d%5Cmu%28%5Cmathbf%7Bs%7D%29%5Cepsilon%28R%29%5Cexp%5B-N%5Cbeta+%5Cepsilon%28R%29%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
where Z is the Partition Function, and 
We call the Quality the Teacher our approximation of the generalization accuracy. The ST quality is simply 1 minus the generalization error, which is Thermal average of the ST overlap

This can also be written using a generating function 


(Although below we will actually compute the layer Quality squared, 
Fixing the Teacher: That’s it. What’s so hard about this ? Normally in Statistical Mechanics, one also has to average over all possible Teachers (T) that look the same — this complicates the story immensely. What we have described this for a fixed Teacher, we will use this as a general formalism to derive the weightwatcher AlphaHat metric.
Our Proposal: We let 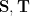
We can think of the class of Student matrices S as all matrices that are close to T. What we really want is the best method for doing this, that has been tested experimentally. Fortunately, Hinton and coworkers have recently revisited Similarity of Neural Network Representations, and found the best matrix similarity method is
Canonical Correlation Analysis (CCA):
![R^{2}:=\tfrac{1}{N^2}Tr[(\mathbf{S}^{\top}\mathbf{T})^{2}]](https://s0.wp.com/latex.php?latex=R%5E%7B2%7D%3A%3D%5Ctfrac%7B1%7D%7BN%5E2%7DTr%5B%28%5Cmathbf%7BS%7D%5E%7B%5Ctop%7D%5Cmathbf%7BT%7D%29%5E%7B2%7D%5D&bg=ffffff&fg=%23000000&s=0&c=20201002)
Using CCA, we can formulate our new, Semi-Empirical Theory with the following conjectures
Conjecture 1: We can write the matrix-generalized Layer Quality in terms of a Thermal Average of the Overlap Squared, averaged over all possible (random) matrices S that resemble the actual (pre-)trained weight matrices T
Let us A the (N x N) Student correlation matrix:

Write the Layer Quality for the Teacher 
![\mathbf{Q}_{\mathbf{T}}\approx\sqrt{\langle \mathbf{Q}^{2}_{\mathbf{T}} \rangle _{\mathbf{S}}^{\beta}}=\sqrt{\langle Tr[\mathbf{R}^{\top}\mathbf{R}] \rangle _{\mathbf{S}}^{\beta}}=\sqrt{\langle \tfrac{1}{N}Tr[\mathbf{T}^{\top}\mathbf{AT}] \rangle _{\mathbf{S}}^{\beta}}](https://s0.wp.com/latex.php?latex=%5Cmathbf%7BQ%7D_%7B%5Cmathbf%7BT%7D%7D%5Capprox%5Csqrt%7B%5Clangle+%5Cmathbf%7BQ%7D%5E%7B2%7D_%7B%5Cmathbf%7BT%7D%7D+%5Crangle+_%7B%5Cmathbf%7BS%7D%7D%5E%7B%5Cbeta%7D%7D%3D%5Csqrt%7B%5Clangle+Tr%5B%5Cmathbf%7BR%7D%5E%7B%5Ctop%7D%5Cmathbf%7BR%7D%5D+%5Crangle+_%7B%5Cmathbf%7BS%7D%7D%5E%7B%5Cbeta%7D%7D%3D%5Csqrt%7B%5Clangle+%5Ctfrac%7B1%7D%7BN%7DTr%5B%5Cmathbf%7BT%7D%5E%7B%5Ctop%7D%5Cmathbf%7BAT%7D%5D+%5Crangle+_%7B%5Cmathbf%7BS%7D%7D%5E%7B%5Cbeta%7D%7D&bg=ffffff&fg=%23000000&s=0&c=20201002)
where 


![Tr[\mathbf{R}^{\top}\mathbf{R}] =\tfrac{1}{N^2}Tr[\mathbf{T}^{\top}\mathbf{S}\mathbf{S}^{\top}\mathbf{T}]= \tfrac{1}{N}Tr[\mathbf{T}^{\top}\mathbf{AT}]](https://s0.wp.com/latex.php?latex=Tr%5B%5Cmathbf%7BR%7D%5E%7B%5Ctop%7D%5Cmathbf%7BR%7D%5D++%3D%5Ctfrac%7B1%7D%7BN%5E2%7DTr%5B%5Cmathbf%7BT%7D%5E%7B%5Ctop%7D%5Cmathbf%7BS%7D%5Cmathbf%7BS%7D%5E%7B%5Ctop%7D%5Cmathbf%7BT%7D%5D%3D+%5Ctfrac%7B1%7D%7BN%7DTr%5B%5Cmathbf%7BT%7D%5E%7B%5Ctop%7D%5Cmathbf%7BAT%7D%5D&bg=ffffff&fg=%23000000&s=0&c=20201002)
Conjecture 2: We can express this Thermal average in terms of an HCIZ integral.
Let us re-define an analogous the layer quality (squared) generating function 


![\Gamma^{IZ}_{\mathbf{Q}^{2}_{T}}:=\ln\int d\mu(\mathbf{S})\exp\left(N\beta \tfrac{1}{N}Tr[\mathbf{T}^{\top}\mathbf{AT}]\right)](https://s0.wp.com/latex.php?latex=%5CGamma%5E%7BIZ%7D_%7B%5Cmathbf%7BQ%7D%5E%7B2%7D_%7BT%7D%7D%3A%3D%5Cln%5Cint+d%5Cmu%28%5Cmathbf%7BS%7D%29%5Cexp%5Cleft%28N%5Cbeta+%5Ctfrac%7B1%7D%7BN%7DTr%5B%5Cmathbf%7BT%7D%5E%7B%5Ctop%7D%5Cmathbf%7BAT%7D%5D%5Cright%29&bg=ffffff&fg=%23000000&s=0&c=20201002)
This is an integral over all random Student matrices S that ‘resemble‘ the Teacher matrix T.
Conjecture 3: We can evaluate this integral over an Effective Correlation Space (ECS), spanned by the Power Law tail of the ESD, subject to a volume-preserving transformation

That is, we can replace the integral over all Student weight matrices 


![\Gamma^{IZ}_{\mathbf{Q}^{2}_{T}}:=\ln\int d\mu(\mathbf{\tilde{A}})\exp\left(\beta Tr[\mathbf{T}^{\top}\mathbf{\tilde{A}T}]\right)](https://s0.wp.com/latex.php?latex=%5CGamma%5E%7BIZ%7D_%7B%5Cmathbf%7BQ%7D%5E%7B2%7D_%7BT%7D%7D%3A%3D%5Cln%5Cint+d%5Cmu%28%5Cmathbf%7B%5Ctilde%7BA%7D%7D%29%5Cexp%5Cleft%28%5Cbeta+Tr%5B%5Cmathbf%7BT%7D%5E%7B%5Ctop%7D%5Cmathbf%7B%5Ctilde%7BA%7DT%7D%5D%5Cright%29&bg=ffffff&fg=%23000000&s=0&c=20201002)
When we evaluate this in the large-N limit, using a (slightly modified) result by Tanaka, shown below:
RMT and HCIZ Integrals
These kinds of integrals traditionally appeared in Quantum Field Theory and String Theory, but also in the context of Random Matrix applied to Levy Spin Glasses, And it is this early work on Heavy-Tailed Random Matrices that has motivated our empirical work. Here, to complement and extend our studies, we lay out an (incomplete) overview of the Theory.
These integrals are called Harish Chandra–Itzykson–Zuber (HCIZ) integrals. A good introductory reference on both RMT and HCIZ integrals the recent book “A First Course in Random Matrix Theory”, although we will base our analysis here on the results of the 2008 paper by Tanaka,
We can now express the log HCIZ integral, in using Tanaka’s result, as an expectation value of all random Student correlations matrices A that resemble X. In the large-N approximation, we have
![\underset{N\rightarrow \text{large}}{lim}\Gamma^{IZ}_{\mathbf{Q}^{2}_{T}}= \underset{N\rightarrow \text{large}}{lim}\log\;\mathbb{E}_{A}\left[exp\left(\beta Tr[\mathbf{T}^{\top}\mathbf{A}\mathbf{T}]\right)\right]=N\beta\sum\limits_{i=1}^{M}\;G_{A}(\lambda_i)](https://s0.wp.com/latex.php?latex=%5Cunderset%7BN%5Crightarrow+%5Ctext%7Blarge%7D%7D%7Blim%7D%5CGamma%5E%7BIZ%7D_%7B%5Cmathbf%7BQ%7D%5E%7B2%7D_%7BT%7D%7D%3D+%5Cunderset%7BN%5Crightarrow+%5Ctext%7Blarge%7D%7D%7Blim%7D%5Clog%5C%3B%5Cmathbb%7BE%7D_%7BA%7D%5Cleft%5Bexp%5Cleft%28%5Cbeta+Tr%5B%5Cmathbf%7BT%7D%5E%7B%5Ctop%7D%5Cmathbf%7BA%7D%5Cmathbf%7BT%7D%5D%5Cright%29%5Cright%5D%3DN%5Cbeta%5Csum%5Climits_%7Bi%3D1%7D%5E%7BM%7D%5C%3BG_%7BA%7D%28%5Clambda_i%29&bg=ffffff&fg=%23000000&s=0&c=20201002)
And this can be expressed as a sum over Generating functions 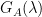
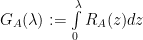
where 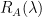
The R Transform is like an inverse Green’s function (i.e a Contour Integral), and is also a cumulant generating function. As such, we can write 

where 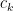
Now, since we expect the best Students matrices resemble the Teacher matrices, we expect the Student correlation matrix A to have similar spectral properties as our actual correlation matrices X. And this where we can use our classification of the 5+1 Phases of Training. Whatever phase X is in, we expect all the A to be in as well, and we therefore expect the R-Transform of A to have the same functional form as X.
Formal Expression for the Layer Quality (squared)
We can now evaluate the derivative of the layer quality squared generating function

where the sum over 

Comments on HCIZ Integrals
Quenched vs Annealed Averages
Formally, we just say we are averaging over all Students A. More technically, what really want to do is fix some Student matrix (i.e. say A = diagonal X), and then integrate over all possible Orthogonal transformations O of A (see 6.2.3 of Potters and Bouchaud)
![\mathbb{E}\left[\log\left\langle\exp\left(\dfrac{\beta}{2}Tr[\mathbf{T}^{\top}\mathbf{O}^{\top}\mathbf{A}\mathbf{OT}]\right)\right\rangle_{\mathbf{O}}\right]_{\mathbf{A}}\simeq\log\mathbb{E}\left[\exp\left(\dfrac{\beta}{2}Tr[\mathbf{T}^{\top}\mathbf{A}\mathbf{T}]\right)\right]_{\mathbf{A}}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Cleft%5B%5Clog%5Cleft%5Clangle%5Cexp%5Cleft%28%5Cdfrac%7B%5Cbeta%7D%7B2%7DTr%5B%5Cmathbf%7BT%7D%5E%7B%5Ctop%7D%5Cmathbf%7BO%7D%5E%7B%5Ctop%7D%5Cmathbf%7BA%7D%5Cmathbf%7BOT%7D%5D%5Cright%29%5Cright%5Crangle_%7B%5Cmathbf%7BO%7D%7D%5Cright%5D_%7B%5Cmathbf%7BA%7D%7D%5Csimeq%5Clog%5Cmathbb%7BE%7D%5Cleft%5B%5Cexp%5Cleft%28%5Cdfrac%7B%5Cbeta%7D%7B2%7DTr%5B%5Cmathbf%7BT%7D%5E%7B%5Ctop%7D%5Cmathbf%7BA%7D%5Cmathbf%7BT%7D%5D%5Cright%29%5Cright%5D_%7B%5Cmathbf%7BA%7D%7D&bg=ffffff&fg=%23000000&s=0&c=20201002)
Then, we integrate over all possible A~diag(X) , which would account for fluctuations in the eigenvalues. We conceptually assume this is the same as integrating over all possible Students A, and then taking the log.
The LHS is called the Quenched Average, and the RHS is the Annealed. Technically, they are not the same, and in traditional Stat Mech theory, this makes a big difference. In fact, in the original Student-Teacher model, we would also average over all Teachers, chosen uniformly (to satisfy the spherical constraints)
Here, we are doing RMT a little differently, which may not be obvious until the end of the calculation. We do not assume a priori a model for the Student matrices. That is, instead of fixing A=diag(X), we will fit the ESD of X to a continuous (power law) distribution 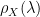
The point is, we want to find an expression for the HCIZ integral (i.e the layer / matrix contribution to the Generalization Error) that only depends on observations of W, the weight matrix of the pretrained DNN (our Teacher network). The result only depends on the eigenvalues of X, and the R-transform of A , which is parameterized by statistical information from X.
In principle, I supposed we could measure the generalized cumulants 

Let us consider 2 classes of matrices as models for X.
Models of the Teacher ESD
That is, if our DNN weight matrix has a Heavy Tailed ESD

then we expect all of the students to likewise have a Heavy Tailed ESD, and with the same exponent (at least for now).
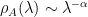
Gaussian (Wigner) Random Matrix: Random-Like Phase
The R-Transform for Gaussian Random matrix is well known:

Taking the integral and plugging this into the Generating function (and assuming A spans the ECS space, which is probably does not BTW), we get

![\sum\limits_{i=1}^{M}\;G_{A}(\lambda_i)=\tfrac{1}{2}\sum\limits_{i=1}^{M}\lambda^{2}_{i}=\tfrac{1}{2}Tr[\mathbf{A}^{2}]](https://s0.wp.com/latex.php?latex=%5Csum%5Climits_%7Bi%3D1%7D%5E%7BM%7D%5C%3BG_%7BA%7D%28%5Clambda_i%29%3D%5Ctfrac%7B1%7D%7B2%7D%5Csum%5Climits_%7Bi%3D1%7D%5E%7BM%7D%5Clambda%5E%7B2%7D_%7Bi%7D%3D%5Ctfrac%7B1%7D%7B2%7DTr%5B%5Cmathbf%7BA%7D%5E%7B2%7D%5D&bg=ffffff&fg=%23000000&s=0&c=20201002)
So when X is Random-Like , the layer / matrix contribution is like the Frobenius Norm (but squared), and thus average Generalization Error is given by a Frobenius Product Norm (squared). Thing is, this is never observed in any production model, as every single model we have examined has a Heavy-Tailed ESD. So we need something else.
Levy Random Matrix: Very Heavy Tailed Phase–but with
As we have argued previously, due to finite size effects, we expect that the Very Heavy Tailed matrices appearing in DNNs will more resemble Levy Random matrices that the Random-Like Phase. So for now, we will close one eye and extend the results for 
![\alpha\in[2,6]](https://s0.wp.com/latex.php?latex=%5Calpha%5Cin%5B2%2C6%5D&bg=ffffff&fg=%23000000&s=0&c=20201002)
The R-Transform for a Levy Random Matrix has been given by Burda
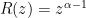
Taking the integral and plugging this into the Generating function, we get
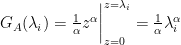
![\sum\limits_{i=1}^{M}\;G_{A}(\lambda_i)=\frac{1}{\alpha}Tr[\mathbf{A}^{\alpha}]](https://s0.wp.com/latex.php?latex=%5Csum%5Climits_%7Bi%3D1%7D%5E%7BM%7D%5C%3BG_%7BA%7D%28%5Clambda_i%29%3D%5Cfrac%7B1%7D%7B%5Calpha%7DTr%5B%5Cmathbf%7BA%7D%5E%7B%5Calpha%7D%5D&bg=ffffff&fg=%23000000&s=0&c=20201002)
where now the matrix A and its eigenvalues (in the tail of the ESD) do indeed span and even defines the ECS space.
Towards our Heavy Tailed Quality Metric
1. Let us pull the power law exponent 
![Tr[\mathbf{A}^{\alpha}]\simeq Tr[\mathbf{A}]^{\alpha}](https://s0.wp.com/latex.php?latex=Tr%5B%5Cmathbf%7BA%7D%5E%7B%5Calpha%7D%5D%5Csimeq+Tr%5B%5Cmathbf%7BA%7D%5D%5E%7B%5Calpha%7D&bg=ffffff&fg=%23000000&s=0&c=20201002)
2. We also assume we can replace the Trace of 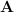

![Tr[\mathbf{A}]=\sum\lambda_{i}\simeq \lambda_{max}](https://s0.wp.com/latex.php?latex=Tr%5B%5Cmathbf%7BA%7D%5D%3D%5Csum%5Clambda_%7Bi%7D%5Csimeq+%5Clambda_%7Bmax%7D&bg=ffffff&fg=%23000000&s=0&c=20201002)
This gives an simple expression for the HCIZ integral expression for the layer contribution to the generalization error

Taking the logarithm of both sides, gives our expression

We have now derived the our Heavy Tailed Quality metric using a matrix generalization of the classic Student Teacher model, with the help of some modern Random Matrix Theory.
QED
I hope this has convince you that there is still a lot of very interesting theory to develop for AI / Deep Neural Networks. And that you will stay tuned for the published form of this work. And remember…
pip install weightwatcher
A big thanks to Michael Mahoney at UC Berkeley for collaborating with me on this work , and to Mirco Milletari’ (Microsoft), who has been extremely helpful. And to my good friend Matt Lee (Triaxiom Capital, LLC) for long discussions about theoretical physics, RMT, quant finance, etc., , and for encouraging me to publish this.
And here’s the Empirical Evidence that this actually works:
https://www.nature.com/articles/s41467-021-24025-8
If you have gotten this far,
and would be willing to read the draft of the real theory paper, that would be great. Please just email me or ping me on Linkedin

2 Comments