AI has taken the world by storm. With recent advances like AlphaFold, Stable Diffusion, and ChatGPT, Deep Neural Networks (DNNs) have had their Sputnik moment. And yet, we really don’t understand why DNNs even work. Unless, of course, you follow this blog and use the widely popular open-source weightwatcher tool.
The open-source weightwatcher tool has been featured in Nature Communications and has over 86K downloads. It can help you diagnose problems in your DNN models, layer-by-layer, without even needing access to the test or training data. But how can weightwatcher possibly do this?
In a previous post, I present the current working theory for the weightwatcher project, which explains where the weightwatcher power law shape metrics alpha 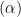

I call this SETOL, a SemiEmpirical Theory of Learning.
We can write the weightwatcher 
![\mathcal{Q}_{\mathbf{T}}\simeq\log\int d\mu(\mathbf{A})\exp\left(Tr[\mathbf{W}^{T}\mathbf{A}\mathbf{W}]\right),](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BQ%7D_%7B%5Cmathbf%7BT%7D%7D%5Csimeq%5Clog%5Cint+d%5Cmu%28%5Cmathbf%7BA%7D%29%5Cexp%5Cleft%28Tr%5B%5Cmathbf%7BW%7D%5E%7BT%7D%5Cmathbf%7BA%7D%5Cmathbf%7BW%7D%5D%5Cright%29%2C+&bg=ffffff&fg=%23000000&s=0&c=20201002)
It is shown in the SETOL paper that when 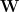
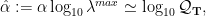
In order to formulate this, however, we need to invoke the change of measure 


where 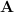

What does this mean? And, more importantly, how can we be sure it is correct ?
The Effective Correlation Space
First, some more familiar notation. More generally, given an arbitrary layer weight matrix 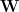

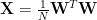
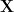

In words, this means that, we need to change our concept of where the generalizing components live and how we effectively measure them.
For a very well-trained DNN layer, the correlations concentrate into a lower rank space, effectively defined by eigenvalues in the power law (PL) tail of the ESD. By this, we mean that there is some effective operator 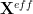

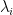
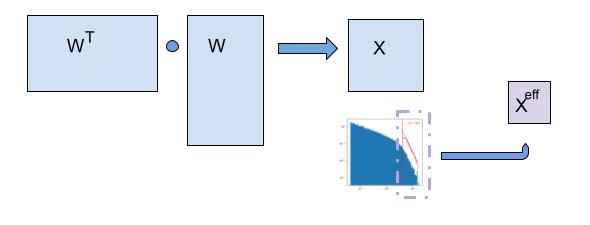
This is consistent with the HTSR theory (published in JMLR), that states that for any well-trained weight matrix, the ESD of the layer not only forms a power law 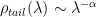
More on what precisely 
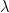
In the rigorous formulation of the weightwatcher theory, to accomplish this, we require that the Effective Correlation Space be defined by a Volume-Preserving Transformation
Volume-Preserving Transformation
if we (crudey) write this transformation in terms of a Jacobian 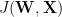

then the Determinant of the Jacobian of this transformation should be the identity, i.e. 
The key assumption of the weightwatcher theory is an empirically verifiable approximation:
- The eigenvalues of the tail of
, satisfy the relation
.
- That is, the effective correlation matrix
,
This means we have now 2 independent methods to identify the power law tail (indicated with a red or purple line.)
- MLE fit: (red line): Apply the standard (Clauset MLE) PL estimator, and find the eigenvalue
where PL the tail starts. This is the default weightwatcher approach.
- det X=1 (purple line): Search for the first eigenvalue
that satisfies condition the
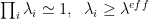
When these 2 methods coincide, we can have great confidence the theory applies well . At least I do.
This constraint can be evaluated empirically by plotting the ESD on a log-linear plot, and comparing the point where to where the PL fit says the tail of the ESD starts (red line) to where the
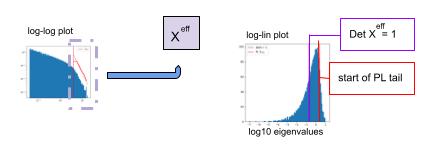
Remarkably, this is very frequently satisfied when the ESD is power law 
Empirical Verification of the (SETOL) Theoretical Model
Here, we will provide some justification for these key assumptions, using the open-source weightwatcher tool. As always, all of these results are 100% reproducible, and, moreover, you can test the assumptions on other models yourself.
As always, you can generate these results yourself on any model you like using weightwatcher. Simply use the following commands in your favorite notebook (Jupyter, Google Colab, etc.):
import weightwatcher as ww
watcher = ww.WeightWatcher()
details = watcher.analyze(model=your_model, plot=True, detX=True)
When the theory is working perfectly, or at least as prescribed, then
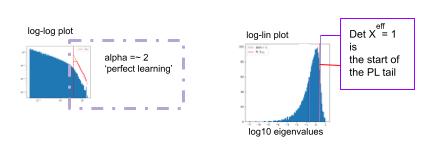
- the weightwatcher Pl shape metric alpha will be about 2:
- the detX constant plot will show the purple (
) lines very close together, if not overlapping.

In the theory paper, we show this for a simple example, however, it turns out, this is very common even in many SOTA models!
Here are some examples from SOTA DNN models
ALBERT
ALBERT (A Lite BERT) is a SOTA LLM published by Google & the University of Chicago; it is a lightweight variant of BERT. It even outperforms, BERT, and XLNet, and RoBERTa in some cases.
There are several ALBERT models (base, large, xlarge, xxlarge), and most have layers have ![\alpha\in [2.5, 4.5]](https://s0.wp.com/latex.php?latex=%5Calpha%5Cin+%5B2.5%2C+4.5%5D++&bg=ffffff&fg=%23000000&s=0&c=20201002)


Notice that the layer averaged alpha metric,
Where the does the SETOL theory work exactly ?
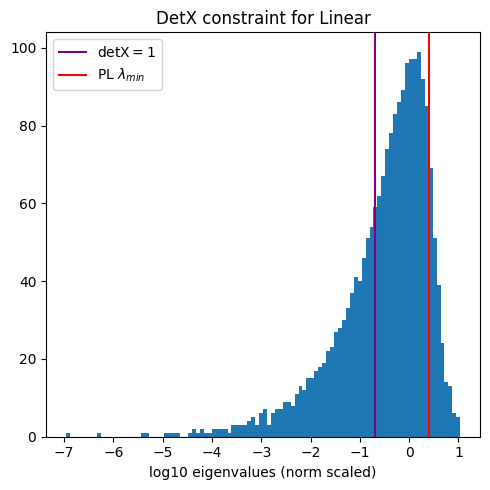
Lets take a look at 2 random layers from. the ALBERT albert-xlarge-v2 model, with different alphas: a middle layer, with 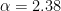

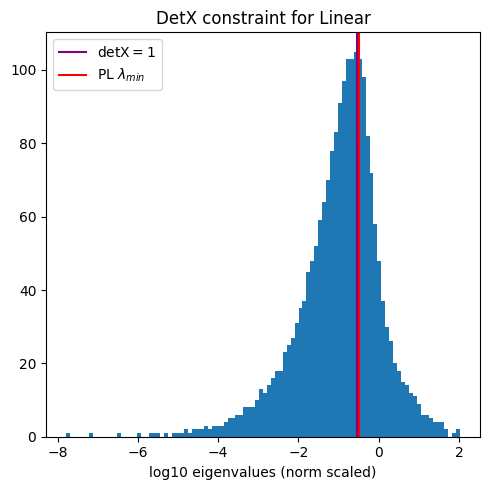
VGG19
We have looked at the VGG series of models before, both in our JMLR paper, and in our Nature Communicationss paper. Here, we look at a couple of Fully Connected (FC) or Dense/Linear layers with alpha near 2.0. (Note, we did this analysis in Table 6, the JMLR paper, but I have found that more recent versions of VGG give different results; here Ireport results from the current, default Keras VGG19 model)

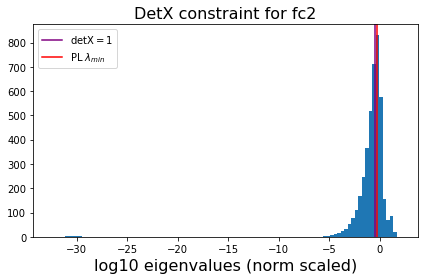
Analysis
Here, despite the 2 plots above looking very different, both alphas are close to 2, and in both cases the purple and red lines overlap, showing that these ESDs exhibit the signatures of the required Volume Preserving Transformation under-the-hood of the rigorous weightwatcher Statistical Mechanics-based Semi-Empirical Theory of Learning (SETOL).
More Models ?
To convince you I am not just cherry-picking examples, let me encourage you to download the open-source weightwatcher tool and try it yourself.
pip install weightwatcher
If you find it works, please let me know. And. if something is wrong, I’d like to know that too.
Closing Points
WeightWatcher is an open-source, diagnostic tool for analyzing Deep Neural Networks (DNN), without needing access to training or even test data. It is based on theoretical research into Why Deep Learning Works, and is described in a new theory–the weightwatcher Semi-Empirical Theory of Learning (SETOL). Here, we have shown a key feature of the new SETOL approach–that DNNs can be described with an Effective Correlation Space at each layer, and that this space is characterized by a Volume Preserving Transformation that captures and concentrates the correlations in the data at each layer. And we have shown how you can test this yourself using the weightwatcher tool.
Most importantly, the empirical results show that when the layer is learning perfectly, the layer correlations can be fit to a heavy-tailed power law (PL) distribution, with PL exponent alpha of 2–exactly as prescribed by the earlier HTSR theory!
If you would like to read an early draft of the new paper, please reach out me. I would greatly appreciate the feedback. Additionally, feel free to join the weightwatcher community Discord channel to discuss all things about the theory and how to use the tool to help you with the training and monitoring of your AI models.
WeightWatcher is a one-of-a-kind must-have tool for anyone training, deploying, or monitoring Deep Neural Networks (DNNs).
The weightwachter tool has been developed by Calculation Consulting. We provide consulting to companies looking to implement Data Science, Machine Learning, and/or AI solutions. Reach out today to learn how to get started with your own AI project. #talkToChuck #theAIguy Email: Info@CalculationConsulting.com

2 Comments