Why Does Deep Learning Work ? If we could get a better handle on this, we could solve some very hard problems in Deep Learning. A new class at Stanford is trying to address this. Here, I review some very new results from my own research (w/UC Berkeley) on the topic which has direct practical application. Here, I will show that
In pretrained, production quality DNNs, the weight matrices for the Fully Connected (FC ) layers display Fat Tailed Power Law behavior.
Setup: the Energy Landscape function
Deep Neural Networks (DNNs) minimize the Energy function defined by their architecture. We define the layer weight matrices 
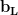
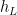
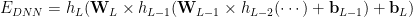
We train the DNN on a labeled data set (d,y), giving the optimization problem
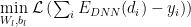
We call this the Energy Landscape because the DNN optimization problem is only parameterized by the weights and biases. Of course, in any real DNN problem, we do have other adjustable parameters, such as the amount of Dropout, the learning rate, the batch size, etc. But these regularization effects simply change the global 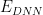
The Energy Landscape function changes on each epoch–and do we care about how. In fact, I have argued that

But here, for now, we only look at the final result. Once a DNN is trained, what is left are the weights (and biases). We can reuse the weights (and biases) of a pre-trained DNN to build new DNNs with transfer learning. And if we train a bunch of DNNs, we want to know which one is better ?
But, practically, we would really like to identify a very good DNN without peaking at the test data, since every time we peak, and retrain, we risk overtraining our DNN.
I now show we can at least start do this by looking the weights matrices themselves. So let us look at the weights of some pre-trained DNNs.
Pretrained Linear Models in Pytorch
Pytorch comes with several pretrained models, such as AlexNet. To start, we just examine the weight matrices of the Linear / Fully Connected (FC) layers.
pretrained_model = models.alexnet(pretrained=True)
for module in pretrained_model.modules():
if isinstance(module, nn.Linear):
...
The Linear layers have the simplest weight matrices 
Let 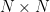
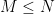
W = np.array(module.weight.data.clone().cpu()) M, N = np.min(W.shape), np.max(W.shape)
Empirical Spectral Density
How is information concentrated in
Singular Value Decomposition (SVD)
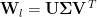

which is readily computed in scikit learn. We will use the faster TruncatedSVD method, and compute singular values 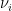
from sklearn.decomposition import TruncatedSVD svd = TruncatedSVD(n_components=M-1, n_iter=7, random_state=10) svd.fit(W) svals = svd.singular_values_
(Technically, we do miss the smallest singular value doing this, but that’s ok. It won’t matter here, and we can always use the pure svd method to be a exact)
Eigenvalues of the Correlation Matrix
We can, alternatively form the eigenvalues of the correlation matrix

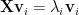
The eigenvalues are just the square of the singular values.
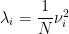
Notice here we normalize them by N.
evals = (1/N)*svals*svals
We now form the Empirical Spectral Density (ESD), which is, formally

This notation just means compute a histogram of the eigenvalues
import matplotlib.pyplot as plt plt.hist(evals, bins=100, density=True)
We could also compute the spectral density using a Kernel Density Estimator (KDE); we save this for a future post.
We now look at the ESD of
Pretrained AlexNet
Here, we examine just FC3, the last Linear layer, connecting the model to the labels. The other linear layers, FC1 and FC2, look similar. Below is a histogram for ESD. Notice it is very sharply peaked and has long tail, extending out past 40.

We can get a better view of the heavy tailed behavior by zooming in.

The red curve is a fit of the ESD to the Marchenko Pastur (MP) Random Matrix Theory (RMT) result — it is not a very good fit. This means ESD does not resemble Gaussian Random matrix. Instead, it is looks heavy tailed. Which leads to the question…
Do we have a Power Law ?
(Yes do, as we shall see…)
Physicists love to claim they have discovered data that follows a power law:

But this is harder to do than it seems. And statisticians love to point this out. Don’t be fooled–we physicists knew this; Sornette’s book has a whole chapter on it. Still, we have to use best practices.
Log Log Histograms
The first thing to do: plot the data on a log-log histogram, and check that this plot is linear–at least in some region. Let’s look at our ESD for AlexNet FC3:

Yes, it is linear–in the central region, for eigenvalue frequencies between roughly ~1 and ~100–and that is most of the distribution.
Why is not linear everywhere? Because it is finite size–there are min and max cutoffs. In the infinite limit, a powerlaw 


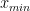
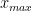
Power Law Fits
Second, fit the data to a power law, with
import powerlaw fit = powerlaw.Fit(evals, xmax=np.max(evals)) alpha, D = fit.alpha, fit.D
The D value is a quality metric, the KS distance. There are other options as well. The smaller D, the better. The table below shows typical values of good fits.
Linear Log Log Plots
The powerlaw package also makes some great plots. Below is a log log plot generated for our fit of FC3, for the central region of the ESD. The filled lines represent our fits, and the dotted lines are actual power lawPDF (blue) and CCDF (red). The filled lines look like straight lines and overlap the dotted lines–so this fit looks pretty good.

Is this enough ? Not yet…
Quality of the Estimator
We still need to know, do we have enough data to get a good estimate for 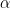
- This so-called statistically valid MLE estimator actually only works properly for
.
- And we need a lot of data points…more than we have singular values
We can calibrate the estimator by generating some modest size (N=1000) random power law datasets using the numpy Pareto function, where

and then fitting these with the PowerLaw package. We get the following curve

The green line is a perfect estimate. The Powerlaw package overestimates small 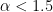

Is a Power law the best model ?
A good fit is not enough. We also should ensure that no other obvious model is a better fit. The power law package lets us test out fit against other common (long tailed) choices, namely
- exponential (EXP)
- stretched_exponential (S_EXP)
- log normal (LOG_N)
- truncated power law (TPL)
For example, to check if our data is better fit by a log normal distribution, we run
R, p = fit.distribution_compare('powerlaw', 'lognormal', normalized_ratio=True)
and R and the the p-value. If if R<0 and p <= 0.05, then we can conclude that a power law is a better model.
Note that sometimes, for 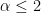
More Pretrained Models: Linear Layers
Below we fit the linear layers of the many pretrained models in pytorch. All fit a power law (PL) or truncated power law (TPL)

The table below lists all the fits, with the Best Fit and the KS statistic D. 
Notice that all the power law exponents lie in the range 2-4, except for a couple outliers.
![\alpha\in[2,4]](https://s0.wp.com/latex.php?latex=%5Calpha%5Cin%5B2%2C4%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
This is pretty fortunate since out PL estimator only works well around this range. This is also pretty remarkable because it suggests there is…
Universality in Deep Learning:
There is a deep connection between this range of exponents and some (relatively) recent results in Random Matrix Theory (RMT). Indeed, this seems to suggest that Deep Learning systems display the kind of Universality seen in Self Organized systems, like real spiking neurons. We will examine this in a future post.
Practical Applications:
Training DNNs is hard. There are many tricks one has to use. And you have to monitor the training process carefully.
Here we suggest that the ESDs of the Linear / FC layers of a well trained DNN will display power law behavior. And the exponents will be between 2 and 4.
Counterexample: Inception V3
A counter example is Inception V3. Both FC layers 226 and 302 have unusually large 
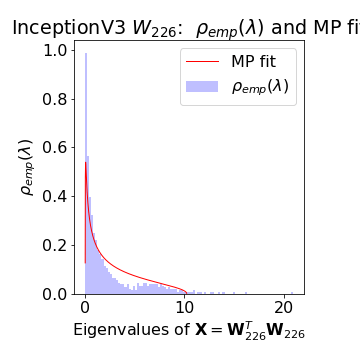
We conjecture that as good as Inception V3 is, perhaps it could be further optimized. It would be interesting to see if anyone can show this.
Appendix:
Derivation of the MLE PowerLaw estimator
The commonly accepted method uses Maximum Likelihood Estimator (MLE). This

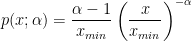

The conditional probability is defined by evaluating 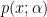

The log likelihood is

Which is easily reduced to
![=\displaystyle\sum_{i=1}^{n}\Big[ln(\alpha-1)-ln(x_{min})-\alpha\;ln\left(\dfrac{x_{i}}{x_{min}}\right)\Big]](https://s0.wp.com/latex.php?latex=%3D%5Cdisplaystyle%5Csum_%7Bi%3D1%7D%5E%7Bn%7D%5CBig%5Bln%28%5Calpha-1%29-ln%28x_%7Bmin%7D%29-%5Calpha%5C%3Bln%5Cleft%28%5Cdfrac%7Bx_%7Bi%7D%7D%7Bx_%7Bmin%7D%7D%5Cright%29%5CBig%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
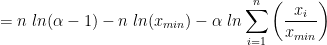
The maximum likelihood occurs when
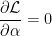
The MLE estimate, for a given 
![\hat{\alpha}=1+n\Big[\displaystyle\sum_{i=1}^{n}ln\dfrac{x_{i}}{x_{min}}\Big]^{-1}](https://s0.wp.com/latex.php?latex=%5Chat%7B%5Calpha%7D%3D1%2Bn%5CBig%5B%5Cdisplaystyle%5Csum_%7Bi%3D1%7D%5E%7Bn%7Dln%5Cdfrac%7Bx_%7Bi%7D%7D%7Bx_%7Bmin%7D%7D%5CBig%5D%5E%7B-1%7D++&bg=ffffff&fg=%23000000&s=0&c=20201002)
We can either input
Notice, however, that this estimator does not explicitly take 
Universality in NLP Models:
Similar results arise in the Linear and Attention layers in NLP models. Below we see the power law fits for 85 Linear layers in the 6 pretrained models from AllenNLP

80% of the linear layers have
Extending this to Convolutional (Conv2D) Layers:
We can naively extend these results to Conv2D layers by extracting all the Conv2D layers directly from the 4-index Tensors back, giving several rectangular 2D matrices per layer. Doing this, and repeating the fits, we find that 90% of the Conv2D matrices fit a power law with 

A few Conv2D of layers show very high exponents. What could this mean?
- The PL estimator is terrible for large exponents. We need to implement a more reliable PL estimator before we can start looking at Conv2D layers
- ~20% of the 2D matrices have
. Again, finite size effects may be affecting the fits since many matrices are quite small.
It will be very interesting to dig into these results and determine if the Power Law exponents display Universality across layers, architectures, and data sets.
Update: 27 Sept 2018
Even more pretrained models are now available in pyTorch…45 models and counting. I have analyzed as many as possible, giving 7500 layer weight matrices (including the Conv2D slices!)

The results are conclusive..the ~80% of the exponents display Universality. An amazing find. With such great results, soon we will release an open source package so you can do analyze your own models.
Jupyter Notebooks
Code for this study, and future work, is available in this repo.
Video Presentations
Research talks are available on my youtube channel. Please Subscribe
The big paper

Very interesting result! I have been thinking along similar lines for some time now. But I did not have any empirical evidence. If I am to draw an analogy with the history of universality in phase transitions then what you have here is the phenomenology of the critical phenomena. The way I understand universality is in terms of symmetries. In this case are the symmetries encoded in the neural net architecture or are they coming from the data or both? From a practical side how can we leverage universality (perhaps even at the level of phenomenology) for transfer learning?
LikeLiked by 1 person
All of these systems are ImageNet results, so it could be the data. Although we are also only looking at the fully connected (FC) layers, so it could also be the symmetry of the FC layers, as opposed to Conv2D layers, which have different symmetry
LikeLiked by 1 person
I am now seeing evidence of universal power law exponents in the Linear Layers of the NLP modes of AllenNLP, with exponents mostly between 2 and 4. These layers are very different, mostly attention layers, very different shapes and different data.
LikeLike
its very cool this might unlock more insight of neural network
LikeLike
M, N = np.min(W.shape), N=np.max(W.shape)
I think the second N= is a typo.
LikeLike
thanks fixed it
LikeLike
If the weights follow a powerlaw distribution than does that mean that deep learning algos are more suitable to predict extreme values (in stock market for example) than standard financial tools like markowitz and autoregressive vectors?
LikeLike
The ideas come from finance so maybe ?
LikeLike