We can learn a lot about Why Deep Learning Works by studying the properties of the layer weight matrices of pre-trained neural networks. And, hopefully, by doing this, we can get some insight into what a well trained DNN looks like–even without peaking at the training data.
One broad question we can ask is:
How is information concentrated in Deep Neural Network (DNNs)?
To get a handle on this, we can run ‘experiments’ on the pre-trained DNNs available in pyTorch.
In a previous post, we formed the Singular Value Decomposition (SVD) of the weight matrices of the linear, or fully connected (FC) layers. And we saw that nearly all the FC Layers display Power Law behavior. And, in fact, this behavior is Universal across models both ImageNet and NLP models.
But this only part of the story. Here, we ask related question–do well trained DNNs weight matrices lose Rank ?
Matrix Rank:
Lets say 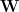
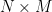


The Matrix Rank 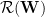


which express the decrease in Full Rank M.

Notice the Hard Rank of the rectangular matrix 
In python, this can be computed using
rank = numpy.linalg.matrix_rank(W)
Of course, being a numerical method, we really mean the number of singular values above some tolerance 
- the default python tolerance
- the numerical recipes tolerance, which is tighter
See the numpy documentation on matrix_rank for details.
Here, we will compute the rank ourselves, and use an extremely loose bound, and consider any 
Rank Collapse and Regularization
If all the singular values are non-zero, we say 
When a model undergoes Rank Collapse, it traditionally needs to be regularized. Say we are solving a simple linear system of equations / linear regression

The simple solution is to use a little linear algebra to get the optimal values for the unknown

But when 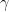


So that all the singular values will now be greater than zero, and we can form a generalized pseudo-inverse, called the Moore-Penrose Inverse

This procedure is also called Tikhonov Regularization. The constant, or Regularizer, 
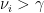

- Information: vectors where
- Noise: vectors where

In cases where
But we know that Understanding deep learning requires rethinking generalization. Which leads to the question ?
Do the weight matrices of well trained DNNs undergo Rank Collapse ?
Answer: They DO NOT — as we now see:
Analyzing Pre-Trained pyTorch Models
We can easily examine the numerous pre-trained models available in PyTorch. We simply need to get the layer weight matrices and compute the SVD. We then compute the minimum singular value 
for im, m in enumerate(model.modules()):
if isinstance(m, torch.nn.Linear):
W = np.array(m.weight.data.clone().cpu())
M, N = np.min(W.shape), np.max(W.shape)
_, svals, _ = np.linalg.svd(W)
minsval=np.min(svals)
...
We do this here for numerous models trained on ImageNet and available in pyTorch, such as AlexNet, VGG16, VGG19, ResNet, DenseNet201, etc.– as shown in this Jupyter Notebook.
We also examine the NLP models available in AllenNLP. This is a little bit trickier; we have to install AllenNLP from source, then create an analyze.py command class, and rebuild AllenNLP. Then, to analyze, say, the AllenNLP pre-trained NER model, we run
allennlp analyze https://s3-us-west-2.amazonaws.com/allennlp/models/ner-model-2018.04.26.tar.gz
This print out the ranks (and other information, like power law fits), and then plot the results. The code for all this is here.
Notice that many of the AllenNLP models include Attention matrices, which can be quite large and very rectangular (i.e. = 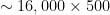
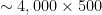
Note: We restrict our analysis to rectangular layer weight matrices with an aspect ratio 

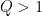
Minimum Singular Values of Pre-Trained Models
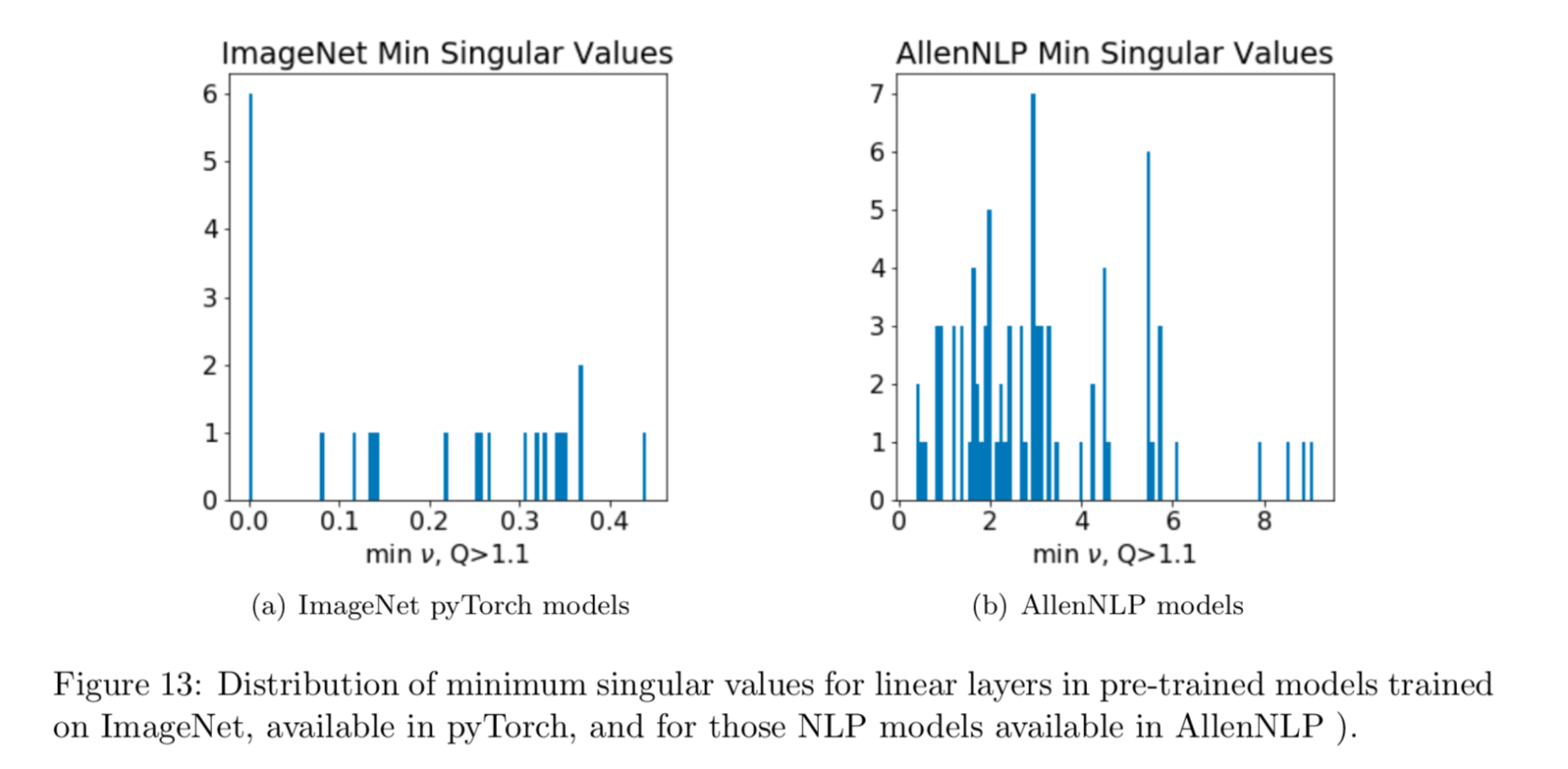
For the ImageNet models, most fully connected (FC) weight matrices have a large minimum singular value 
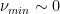
For the AllenNLP models, none of the FC matrices show any evidence of Rank Collapse. All of the singular values for every linear weight matrix are non-zero.
It is conjectured that fully optimized DNNs–those with the best generalization accuracy–will not show Rank Collapse in any of their linear weight matrices.
If you are training your own model and you see Rank Collapse, you are probably over-regularizing.
Inducing Rank Collapse is easy–just over-regularize
it is, in fact, very easy to induce Rank Collapse. We can do this in a Mini version of AlexNet, coded in Keras 2, and available here.
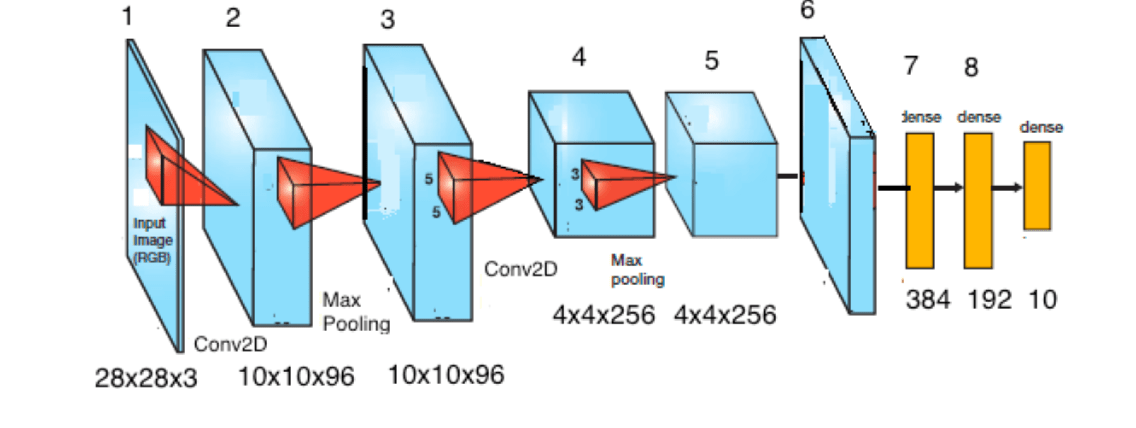
To induce rank collapse in our FC weight matrices, we can add large weight norm constraints to the FC1 linear layer, using the kernel_initializer=…
... model.add(Dense(384, kernel_initializer='glorot_normal', bias_initializer=Constant(0.1),activation='relu', kernel_regularizer=l2(...)) ...
We train this smaller MiniAlexnet model on CIFAR10 for 20 epochs, save the final weight matrix, and plot a histogram of the eigenvalues 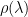
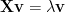
We call


Here is what happens to 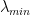
As we increase the weight norm constraints, the minimum eigenvalue approaches zero

Note that adding too much regularization causes nearly all of the eigenvalues/singular values to collapse to zero–as well as the norm of the matrix.
We conjecture that DNNs have zero singular/eigenvalues because there is too much regularization on the layer.
And that…
Fully optimized Deep Neural Networks do not have Rank Collapse
Implications
We believe this is a unique property of DNNs, and related to how Regularization works in these models. We will discuss this and more in an upcoming paper
Implicit Self-Regularization in Deep Neural Networks: Evidence from Random Matrix Theory and Implications for Learning
by Charles H. Martin (Calculation Consulting) and Michael W. Mahoney (UC Berkeley).
And presented at UC Berkeley this Monday at the Simons Institute
and see our long form paper
Please stay tuned and subscribe to this blog for more updates
Appendix
Rank Loss: numerical details
Here we are just looking at the distribution 
In the numpy.linalg.matrix_rank() funtion, “By default, we identify singular values less than S.max() * max(M.shape) * eps as indicating rank deficiency” when using SVD
But there is some ambiguity here as well, since there is a different default from Numerical Recipes. I will leave it up to the reader to select the best rank loss metric and explore further. And I would be very interested in your findings.
40 models and 7500 matrices
We have computed the minimum singular value
![]()
Very generously, we can say there is rank collapse with 

2 Comments