What is the purpose of a theory ? To explain why something works. Sure. But what good is a theory (i.e VC) that is totally useless in practice ? A good theory makes predictions.
Recently we introduced the theory of Implicit Self-Regularization in Deep Neural Networks. Most notably, we observe that in all pre-trained models, the layer weight matrices display near Universal power law behavior. That is, we can compute their eigenvalues, and fit the empirical spectral density (ESD) to a power law form:
For a given 
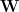
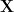

and then compute the M eigenvalues 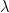
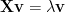
We call the histogram of eigenvalues 
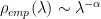
We call the Power Law Universal because 80-90% of the exponents 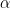
![\alpha\in[2,4]](https://s0.wp.com/latex.php?latex=%5Calpha%5Cin%5B2%2C4%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
For fully connected layers, we just take 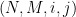


As with the FC layers, we find that nearly all the ESDs can be fit to a power law, and 80-90% of the exponents like between 2 and 4. Although compared to the FC layers, for the Conv2D layers, we do see more exponents 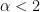
Are power law exponents correlated with better generalization accuracies ? … YES they are!
We can see this by looking at 2 or more versions of several pretrained models, available in pytorch, including
- Inception V3 vs V4
- SqueezeNet V1.0 vs V1.1
- The DenseNet models
- The ResNext101 models
- The sequence of (larger) Resnet models, including Resnet18, 34, 50, 101, & 152
- 2 other ResNet implementations, CaffeResnet101 and FbResnet152
To compare these model versions, we can simply compute the average power law exponent 
The only significant caveats are:
- The VGG models behave very differently, showing exactly the reverse trend !
- The smaller ResNet models (ResNet10, 18, …) also show the reverse trend.
Predicting the test accuracy is a complicated task, and IMHO simple theories , with loose bounds, are unlikely to be useful in practice. Still, I think we are on the right track
Lets first look at the DenseNet models
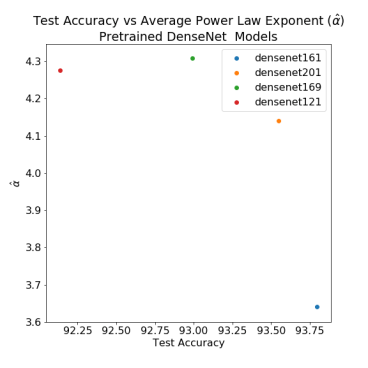
Here, we see that as Test Accuracy increases, the average power law exponent generally decreases. And this is across 4 different models.
The Inception models show similar behavior:  InceptionV3 has smaller Test Accuracy than InceptionV4, and, likewise, the InceptionV3
InceptionV3 has smaller Test Accuracy than InceptionV4, and, likewise, the InceptionV3
Now consider the Resnet models, which are increasing in size and have more architectural differences between them:
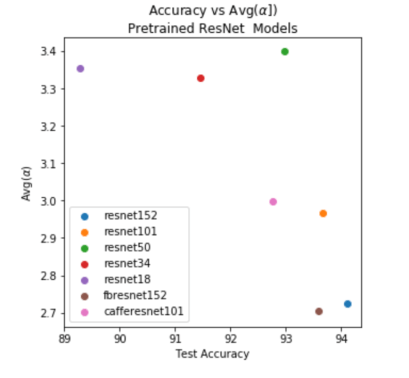
Across all these Resnet models, the better Test Accuracies are strongly correlated with smaller average exponents. The correlation is not perfect; the smaller Resnet50 is an outlier, and Resnet152 has a s larger
These results are easily reproduced with this notebook.
This is an amazing result !
You can think of the power law exponent as a kind of information metric–the smaller
Suppose you are training a DNN and trying to optimize the hyper-parameters. I believe by looking at the power law exponents of the layer weight matrices, you can predict which variation will perform better–without peeking at the test data.
In addition to DenseNet, Inception, ResNext, SqueezeNet, and the (larger) ResNet models, we have even more positive results are available here on ~40 more DNNs across ~10 more different architectures, including MeNet, ShuffleNet, DPN, PreResNet, DenseNet, SE-Resnet, SqueezeNet, and MobileNet, MobileNetV2, and FDMobileNet.
I hope it is useful to you in training your own Deep Neural Networks. And I hope to get feedback from you as to see how useful this is in practice.

Did you batchnorm all the models? I feel if the outputs of layers are not standardized this phenomenon will occur? If you did that’s really interesting.
LikeLiked by 1 person
These are pretrained models; I did not train them. VGG16_BN has BatchNorm for sure.
LikeLike
What would be the alpha of an untrained model?
LikeLike