Power Law Distributions in Deep Learning
In a previous post, we saw that the Fully Connected (FC) layers of the most common pre-trained Deep Learning display power law behavior. Specifically, for each FC weight matrix 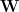

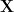

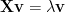
For every FC matrix, the eigenvalue frequencies
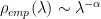
where the exponents 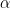
![\alpha\in[2,4]](https://s0.wp.com/latex.php?latex=%5Calpha%5Cin%5B2%2C4%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
Remarkably, the FC matrices all lie within the Universality Class of Fat Tailed Random Matrices!
Heavy Tailed Random Matrices
We define a random matrix by defining a matrix 

- Gaussian Random Matrix:
, where
is a Gaussian distribution
or a
- Heavy Tailed Random Matrix:
, where
is a power law distribution
In either case, Random Matrix Theory tells us what the asymptotic form of ESD should look like. But first, let’s see what model works best.
AlexNet FC3
First, lets look at the ESD 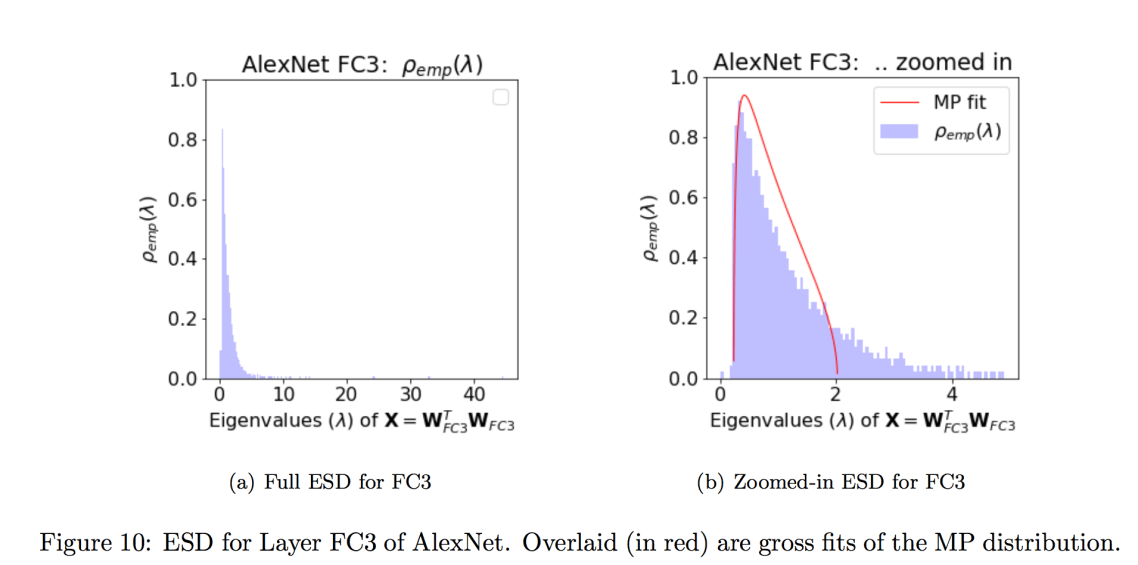
Recall that AlexNet FC3 fits a power law with exponent $\alpha\sim&bg=ffffff $ , so we also plot the ESD on a log-log scale

AlexNet Layer FC3 Log Log Histogram of ESD
Notice that the distribution is linear in the central region, and the long tail cuts off sharply. This is typical of the ESDs for the fully connected (FC) layers of the all the pretrained models we have looked at so far. We now ask…
What kind of Random Matrix would make a good model for this ESD ?
ESDs: Gaussian random matrices
We first generate a few Gaussian Random matrices (mean 0, variance 1), for different aspect ratios Q, and plot the histogram of their eigenvalues.
N, M = 1000, 500 Q = N / M W = np.random.normal(0,1,size=(M,N)) # X shape is M x M X = (1/N)*np.dot(W.T,W) evals = np.linalg.eigvals(X) plot.hist(evals, bins=100,density=True)

Notice that the shape of the ESD depends only on Q, and is tightly bounded; there is, in fact, effectively no tail at all to the distributions (except, perhaps, misleadingly for Q=1)
ESDs: Power Laws and Log Log Histograms
We can generate a heavy, or fat-tailed, random matrix as easily using the numpy Pareto function
W=np.random.pareto(mu,size=(N,M))
Heavy Tailed Random matrices have a very ESDs. They have very long tails–so long, in fact, that it is better to plot them on a log log Histogram
Do any of these look like a plausible model for the ESDs of the weight matrices of a big DNN, like AlexNet ?
- the smallest exponent,
(blue), has a very long tail, extending over 11 orders of magnitude. This means the largest eigenvalues would be
. No real W would behave like this.
- the largest exponent,
(red), has a very compact ESD, resembling more the Gaussian Ws above.
- the fat tailed
ESD (green), however, is just about right. The ESD is linear in the central region, suggesting a power law. It is a little too large for our eigenvalues , but the tail also cuts off sharply, which is expected for any finite W . So we are close
AlexNet FC3
Lets overlay the ESD of fat-tailed W with the actual empirical

We see a pretty good match to a Fat-tailed random matrix with 
Turns out, there is something very special about 
Universality Classes:
Random Matrix Theory predicts the shape of the ESD , in the asymptotic limit, for several kinds of Random Matrix, called University Classes. The 3 different values of

In particular, if we draw 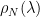
What is more, the predicted ESDs have different, characteristic global and local shapes, for specific ranges of
the ESDs of the fully connected (FC) layers of pretrained DNNs all resemble the ESDs of the ![\mu\in[2,4]](https://s0.wp.com/latex.php?latex=%5Cmu%5Cin%5B2%2C4%5D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
But this is a little tricky to show, because we need to show that
Relations between and 
RMT tells us that, for 

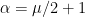
And this works pretty well in practice for the Heavy Tailed Universality Class, for 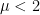
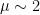
Statistics of the maximum eigenvalue(s)
RMT not only tells us about the shape of the ESD; it makes statements about the statistics of the edge and/or tails — the fluctuations in the maximum eigenvalue 
- Gaussian RMT:
- Fat Tailed RMT:


For standard, Gaussian RMT, the 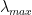

But for 
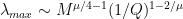
In particular, the effects of M and Q kick in as soon as
And, for us, this affects how we estimate 
Fat Tailed Matrices and the Finite Size Effects for
Here, we generate generate ESDs for 3 different Pareto Heavy tailed random matrices, with the fixed M (left) or N (right), but different Q. We fit each ESD to a Power Law. We then plot


The red lines are predicted by Heavy Tailed RMT (MP) theory, which works well for Heavy Tailed ESDs with
We can identify finite size matrices W that behave like the the Fat Tailed Universality Class of RMT (
Implications
It is amazing that Deep Neural Networks display this Universality in their weight matrices, and this suggests some deeper reason for Why Deep Learning Works.
Self Organized Criticality
In statistical physics, if a system displays a Power Laws, this can be evidence that it is operating near a critical point. It is known that real, spiking neurons display this behavior, called Self Organized Criticality
It appears that Deep Neural Networks may be operating under similar principles, and in future work, we will examine this relation in more detail.
Jupyter Notebooks
The code for this post is in this github repo on ImplicitSelfRegularization
The big paper

4 Comments