Why Deep Learning Works: Self Regularization in DNNs
An early talk describing details in this paper
Presented at UC Berkeley / NERSC Jun 8, 2018
Empirical results, using the machinery of Random Matrix Theory (RMT), are presented that are aimed at clarifying and resolving some of the puzzling and seemingly-contradictory aspects of deep neural networks (DNNs). We apply RMT to several well known pre-trained models: LeNet5, AlexNet, and Inception V3, as well as 2 small, toy models.
We show that the DNN training process itself implicitly implements a form of self-regularization associated with the entropy collapse / information bottleneck. We find that the self-regularization in small models like LeNet5, resembles the familar Tikhonov regularization

whereas large, modern deep networks display a new kind of heavy tailed self-regularization.

We characterize self-regularization using RMT by identifying a taxonomy of the 5+1 phases of training.

Then, with our toy models, we show that even in the absence of any explicit regularization mechanism, the DNN training process itself leads to more and more capacity-controlled models. Importantly, this phenomenon is strongly affected by the many knobs that are used to optimize DNN training. In particular, we can induce heavy tailed self-regularization by adjusting the batch size in training, thereby exploiting the generalization gap phenomena unique to DNNs.
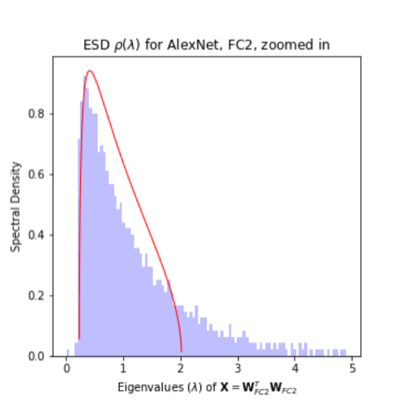
We argue that this heavy tailed self-regularization has practical implications both designing better DNNs and deep theoretical implications for understanding the complex DNN Energy landscape / optimization problem.

1 Comment