One of the most repeated mantra’s of Machine Learning is that “A Causation is not a Correlation!” When faced with…

Thoughts on Data Science, Machine Learning, and AI
One of the most repeated mantra’s of Machine Learning is that “A Causation is not a Correlation!” When faced with…
Today I am going to look at a very important advance in one of my favorite Machine Learning algorithms, NMF…
cloud-crawler-0.1 For the past few weeks, I have taken some time off from pure math to work on an open…
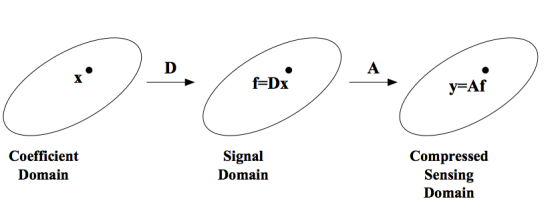
Introduction: In an much earlier post, we looked at detecting Gravity Waves using Machine Learning and techniques like Minimum Path…

Recently , 7 Italian Scientists have been sentenced in prison for manslaughter for failing to predict an Earthquake in 2009 !…

Today we consider the problem of modeling periodic behavior in a noisy time series. This is an old problem from…
Previously we developed some intuition behind the Radial Basis Function / Gaussian Kernel by looking at its Fourier components. We learned that…
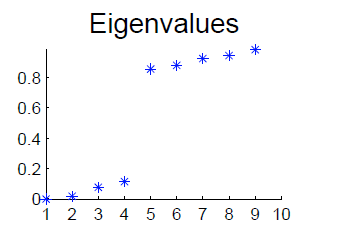
A lot of my ideas about Machine Learning come from Quantum Mechanical Perturbation Theory. To provide some context, we need…
Machine Learning uses Kernels. At least it tries when it can. A Kernel is an operator on a Hilbert Space.…
This post is still just sketch of ideas…not ready for consumption In my last post I introduced the Eigenvalue-Dependent Effective (Semantic)…
