Machine Learning uses Kernels. At least it tries when it can.
A Kernel is an operator on a Hilbert Space. Or we might say that it defines the Hilbert Space. Depends on our point of view.
Typically the Kernels in Machine Learning are quite simple , 1-dimensional, analytic functions, such as the Radial Basis Function (RBF) Kernel

By analytic we mean that the function can be expressed locally as a convergent power series.
Recall that we can express an RBF Kernel as convergent power series via the Fourier Transform
https://charlesmartin14.wordpress.com/2012/02/06/kernels_part_1

Recall also we showed how to construct a Kernel — here a continuously parameterized metric — as a re-summation of a discrete basis set:
https://charlesmartin14.wordpress.com/2012/09/06/kernels-part-2-affine-quantum-gravity-continued
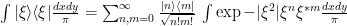

Here, I expand on this concept, and show to construct a special kind of Kernel, called the Resolvent Operator (R), from a convergent power series as a re-summation of a simpler Kernel (K) ,
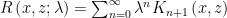
In some later posts, we will show some examples and even try to do some new kinds of machine learning using methods build with the Resolvent Operator. But first, we need to review a little bit about
Kernels, Green’s Functions, and Integral Equations
In Machine Learning, we see the Kernel Trick as a way to expand a dot product

Generally speaking, Kernels arise in the solution of
Linear Integral Equations

These equations take 3 forms
for all
Inverse Problems
for all
I spent the first decade of my career solving the second kind and the second decade solving the first kind. I would now like to see if I can apply the second kind to Machine Learning. But first, some notation and review. For simplicity, we consider 1-dimensional integrals, and let
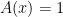
Linear Integral Equations of the First Kind:

where the integrations limits (a,b) do not appear inside the integral.
The workhorse of Machine Learning, most practioners model their data using a simple linear inverse equation, perhaps with some simple non-linear Kernel or even a data-dependent one.
Greens Functions
Frequently, we can express the equation in terms of another linear (differential) operator 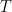

Then we refer to the Kernel as the Greens Function 

Example: the Laplacian and the Brownian Bridge Kernel
We sometimes view of the Graph Laplacian L in Machine Learning as a discrete approximation of the differential operator

For convenience, let us restrict ourself to the domain ![\Omega=[0,1]](https://s0.wp.com/latex.php?latex=%5COmega%3D%5B0%2C1%5D+&bg=%23ffffff&fg=%23000000&s=0&c=20201002)



it can be shown that




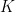
Convolution Operator
When the Kernel 

and we can readily apply techniques such as the Fourier Transform to better understand it (as we did in our first post)
Linear Integral Equations of the Second Kind


The workhorse of Mathematical Physics, this model explicitly incorporates a kind of time or spatial dependence, such as in a time-dependent differential equation. We don’t see these explicitly in Machine Learning, however, there are many approaches to model spatial and time dependencies such as Hidden Markov Models, Conditional Random Fields, Observable Operator Models, etc. We shall look at these in a future blog post.
Is this approach only for time-dependent, Markov processes? The short answer-No. Many time dependent problems can be transformed into time-independent problems, and vice versa. A great example is the Holographic Principle in Quantum Gravity (another post, I promise, soon). So do not be too concerned with time; let us just consider what the final Kernel solution looks like.
The Resolvent Operator
We seek a solution 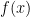
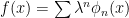
then we have the leading term in the solution (

and the higher order (n) terms are generated by applying the Kernel n times




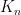
We can now re-sum the applied Kernels to obtain the
If we can find this, we can find our the general solution g from the Resolvent R and the starting function f

We typically don’t see the Resolvent as an infinite sum. Instead, we assume the sum converges and just write
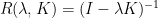
There we have it. We now see the relation between the Kernel’s of machine learning, used to solve Inverse problems, with the Resolvent Operators in mathematical physics, used to solve Inhomogeneous Integral Equations (of the second kind)
Resolvents in Machine Learning: Kernels on Graphs
An example is the Regularized [Graph] Laplacian in equation (17) of
Smola and Kondor, Kernels on Graphs, http://enpub.fulton.asu.edu/cseml/07spring/kenel_graphs.pdf

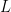
Notice that Smola and Kondor relate their Graph Kernels to Page Rank and HITS. Here we can see a connection: HITS (and to some extend PageRank) is essentially equivalent to finding the principle eigenvector of the associated Markov matrix for the web graph. Solving an eigenvector problem is, in fact, a Linear Integral Equation of the Second Kind (where 
In our next post, we look at Graph Laplacians and their usefulness in Spectral Clustering: A Quick Overview.
Later, (much later), we will show to combine the Resolvent Operators with Projection Operators to form an approach that looks a lot like Bayesian modeling for these classes of equations.

3 Comments