Introduction
Frequently in science, simple models work well beyond their expected range of accuracy and application, and can be essential to provide intuition and insight. Consquently, great effort goes into seaching for simple models that encompass only a few relevant variables and yet provide high accuracy, low bias, and good generalizability.
For example, in my former life as a Quantum Chemist, we constructed simple, semi-empirical models to predict the color of small pigment molecules. The models were simple in that they were linear operators and that they explicitly treated only a small subset of the complete number of possible variables (i.e. only the 
http://pubs.acs.org/doi/abs/10.1021/jp960617w
These semi-empirical
In this post I will describe a new approach to Machine Learning and Feature Dimensional Reduction using what I call an Effective Regression Operator.
Linear Regression
Consider the standard linear model for a regression (ala Smale: http://www.ams.org/notices/200305/fea-smale.pdf )
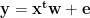
where 

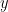





The machine learning/regression problem is to find that operator w that best statisfies our model. Typically this problem is over-determined; one takes a number of measurements (m), leading to a set of linear equations:

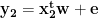
…

We may group these m equations together by grouping the measurement vectors (
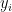
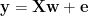
where y and e 

The goal is to find the optimal linear operator w which satisfies this equation.
Normal Equations
To solve the problem, let us first rewrite the linear regression using the normal equations :
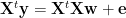
The common solution (again, assuming normal errors) is the ordinary least squares (OLS) solution, found by constructing the Moore-Penrose Pseudoinverse of

Regularization
Ridge Regression
Frequently the matrix 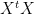

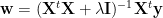
This is also known as Ridge regression. The regularization term 

Notice that, in general, the final model for 
Tikhonov Regularization
We may regularize the ill-conditioned inverse operator 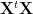

This is called Tikhonov Regularization. We call 


We shall see that our Effective Operator takes the form of a generalized Tikhonov Regularization.
Feature Partitioning: Visible and Hidden Variables
The fundamental assumption driving our approach is to explicitly partition the features into visible (P) and hidden (Q) features in order to explicitly reduce the dimensions of the problem
Let us partition our feature vector x into two subspaces (denoted P and Q), where the P subspace (the Primary space) contains features 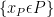


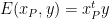


We associate P with the visible features and Q with the hidden features
For each subspace P and Q, we identify the associated projection operators 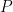
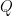


As usual, the projections operators are idempotent:
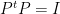
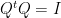
We denote the P and Q parts of the vectors using subscripts. For example, we write the primary features as 

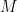


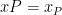
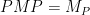
We may now re-write above the normal equations (1) . First, for convenience, define
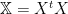
We may express this in block form as:

Now re-write this in block form (ignoring the error vector e) as
![[\begin{array}{cc} P\mathbb{X}P & P\mathbb{X}Q\\ Q\mathbb{X}P & Q\mathbb{X}Q \end{array}]\begin{array}{c} Pw\\ Qw \end{array}= \begin{array}{c} (PX)^{t}y\\ (QX)^{t}y \end{array}](https://s0.wp.com/latex.php?latex=%5B%5Cbegin%7Barray%7D%7Bcc%7D+P%5Cmathbb%7BX%7DP+%26+P%5Cmathbb%7BX%7DQ%5C%5C+Q%5Cmathbb%7BX%7DP+%26+Q%5Cmathbb%7BX%7DQ+%5Cend%7Barray%7D%5D%5Cbegin%7Barray%7D%7Bc%7D+Pw%5C%5C+Qw+%5Cend%7Barray%7D%3D+%5Cbegin%7Barray%7D%7Bc%7D+%28PX%29%5E%7Bt%7Dy%5C%5C+%28QX%29%5E%7Bt%7Dy+%5Cend%7Barray%7D+&bg=ffffff&fg=%23000000&s=0&c=20201002)
This leads to two seperate linear equations (using subscripts from now on)

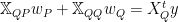
Effective Regression Operator:  :
:
As a approximation, let us assume the hidden, Q-space variables are not coupled at all with the labels 

This lets us write a simple expression for the hidden variable weight vector 

Substituting for

We now define the Effective Regression Operator 
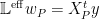
where
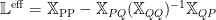
The Effective Operator
Generalizing Tikhonov Regularization
The Effective Regression Operator

and where the Tikhonov matrix 

We may also write an formal expression for the Green’s Function 
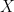


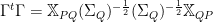
yielding
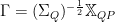
We now see a simple interpretation of the Effective Operator
In a later post we will also examine some real world examples and also see the Fock Space / Second Quantization formulation.
Appendix
Series Expansion Approximation
The term 
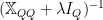
It may not be enough to simply regularize the problem. Additionally, we will most likely need to regularize 
We might hope to avoid a difficult matrix inversion by approximating 

For example, let us split 



and


so that
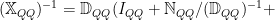
leading to simple expression to first order, with no matrix inverson necessary:
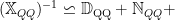
Exact Effective Linear Regression: the Unbiased Solution
Let us now consider the general case of effective regression, where 


Within this formalism, one may then effectively de-noise the solution by creating approximations to 
Going back to equation (3)
we write an exact expression for

Plugging this expression for

or, collecting terms, we get
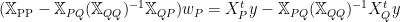
This is significantly harder to solve because the effective equations are highly non-linear and the inverse operator
Note: I developed most of these ideas in 2001. Subsequently, I have learned of some related approaches in the field of Gaussian Processes and Bayesian Regression that use the techniques of Hilbert Spaces and Projection Operators, such as Huaiyu Zhu, Christopher K. I. Williams, Richard Rohwer & Michal Morciniec, Gaussian Regression and Optimal Finite Dimensional Linear Models
One day I will sit down and try to determine the detailed relationship between these works.

Interesting. How do you know that the strategy of partitioning the feature vector into hidden and visible pieces will work? It seems a bit ad hoc. On that note, can you offer any motivation for the tinkanov regularization? I know this is standard practice, but why does it work? Perhaps we can discuss more in detail sometime.
LikeLike
There are two basic conditions for the method: 1, that the Q-space features are only weakly correlated with the labels, compared to the P-space and 2. that the Q-space coupling operator (Q*Q) be invertible. Note that even when Q*Q is ill conditioned, it can be regularized. Many problems are dominated by a single set of features, and adding features only incrementally improves the solution. Although it is unclear to me if the simple solution can be used (4a, b), or one needs the full blown highly non-linear one. Notice that (4a,b) can be cast solved a convex optimization. The real problem with regularization is that unless the final problem is convex, it is hard to find a stable solution
On Tikhonhov Regularization: If the problem is ill-conditioned, then there may be more than 1 solution. The Tikhonhov Regularizer simply constrains the problem to select a single solution that is sparse. Other Regularizers, such as a Radial Basis Function (RBF) Kernel, will select the solution that is most smooth (sparse in ‘derivative space’). (See my earlier post)
We can discuss in detail and I am happy to blog more. Gives me something to do.
LikeLike
I thought of another important example–when you only have a subset of the labels. Indeed, this was the original motivation for this method, which I invented way back in 2001. I will provide an example of this
LikeLike
see : https://charlesmartin14.wordpress.com/2012/09/18/effective-operators-part-2-simple-semisupervised-learning/
LikeLike