What is a Kernel? Really? What is the actual mathematical motivation?
Most machine learning texts introduce the Kernel as some horribly abstract , infinite, continuous operator. It is seemingly disconnected from the problem at hand; one simply need choose any Kernel, cross-validate, cross-validate and cross-validate, and a good solution will emerge.
Or, the Kernel is just some positive definite matrix, constructed from some finite basis set. So what’s with all the formalism if this is all the Kernel is?
In Quantum Physics, and in particular (Affine) Quantum Gravity (ala Klauder: http://www.phys.ufl.edu/~klauder ), the Kernel representation of the Hilbert Space plays the role of connecting the continuous space of Classical Physics to the discrete representation of Quantum Mechanics. Let’s take a look.
Let’s start small–at the Quantum level–and define a discrete but infinite basis of functions , say 

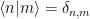

We now will implement what I call the Actual Kernel Trick. We can convert our basis of discrete functions 

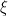
(There are many such resummations; this particular form generates the so-called squeezed states, or coherent states, of quantum dynamics. More on this later)
Notice these states are no longer orthonormal:
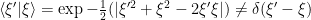
This means that in order to express the Resolution of the Identity Operator , we need to redfine the measure on the space. Here, we change 

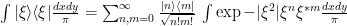

This is why we need to keep track of the Kernel when computing dot products–the measure on the space has changed.
To satisfy the mathematical conditions for Kernel, we should also check that the new functions 
Again, the actual intent of the Kernel Trick is to allow us to represent a infinite set of discrete functions with a family of continuous functions. And in many cases in machine learning, we can express our dot products 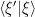
Notice that this is exactly what we accomplished in our previous post: we converted the Radial Basis Function (RBF) Kernel into an infinite sum of spatial derivative operators. And this is exactly the point. We don’t specify a Kernel to just randomly guess what is going on ! We specify the Kernel to provide a compact, even analytic, representation of our prior knowledge of the problem.
I think that’s enough for tonight. In our next post, I will address some actual physics.

As a physicist taking a machine learning class, I found your post illuminating and thought-provoking. Thanks for writing it!
LikeLike
thanks.
LikeLike