 This would not be a pedagogic machine learning blog if I did not go into some overly abstract formalism…here we introduce the Kernel formalism using the languages of Coherent States: We define a space of labels
This would not be a pedagogic machine learning blog if I did not go into some overly abstract formalism…here we introduce the Kernel formalism using the languages of Coherent States: We define a space of labels 




- The map is jointly (and weakly) continuous in
:
- We can define a positive measure on
, that relates back to our measure on

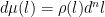
Note that
- if the labels are non-zero, the associated density (in
- We can normalize or label states as
- define the resolution of identify on



In Machine Learning, we specify a Reproducing Kernel Hilbert Space (RKHS) , which is weaker than specifying a full Resolution of the Identity operator. Furthermore, to be really technical, the RKHS we speak of in machine learning are , in fact, a subset of all RKHS that have continuous (and even analytic) Kernels. Let’s compare:
Resolution of Identity
We may express function 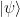

where we identify the continuous function

Reproducing Kernel Hilbert Spaces
You may recall that Dirac invented his notation , the Dirac delta-function, and many other constructs without having a purely rigorous mathematical formulation. As such, I think the machine learning community is trying to start off as rigorously correct as they can.
So rather than introduce an expression for 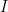


Our “basis set” expansion for 
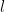


We have some conditions on 


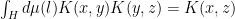
In physics, we typically see these Kernels arising in Integral equations and Inhomogenous differential equations, and as Propagators, Green’s functions, Resolvent Operators, Effective Hamiltonians, etc. They are everywhere! The main difference is that in other fields, one (usually) tries to use their prior knowledge of the problem to actually find the solution and does not just guess random Kernels and crossvalidate (although there are important cases where it does seem like this, such as in Quantum Chemical Density Functional Theory).
What’s the difference?
In the simplest sense, the Kernel takes the place of a Dirac delta function when the basis functions are non-orthogonal. But we handle this by changing the measure on the Resolution of the Identity operator. No sweat.
It is, of course, nice to have a solid, rigorous foundation, but the notation can get cumbersome when we are confined by it to handle special cases that never occur. We tell students that we can do not need to guarantee that the Kernel operator factors, such that

Usually we see this factorization in terms of the inverse Kernel and the Regularization Operator

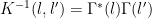
[A related mathematical problem arises in the construction of the Effective Operators in Quantum Chemistry and Physics. Namely, when can an effective operator 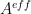

This is quite confusing to the uninitiated or those lacking significant mathematically training , because it makes it seem that the Kernels are random and without physical intuition and insight.
This leads me to ask a question: Are there any useful Kernel in Machine Learning that can not be represented using the Resolution of Identity (or, equivalently, with the associated Regularization Operator) ?
I would accept this recent paper on Reproducing Kernel Banach Spaces with the ℓ1 Norm
Physics of Coherent States
In Physics, we may think of the labels as the Classical variables of phase space 
 To understand this better, we will look at some explicit constructions of this map using both our explicit series expansion construction of Coherent States , Wavelets, as well as using Group Theoretic methods. At some point (maybe part 17 of this blog) I will try to get Coherent states that appear in Affine Quantum Gravity, in Loop Quantum Gravity, and in String Theory. More importantly, for understanding machine learning, we will see the mathematical formulation of Frame Quantization and the attempts to capture the mathematics of coherent states under a single mathematical formalism (and how and when this is doable) . Please stay tuned , ask questions, and post comments.
To understand this better, we will look at some explicit constructions of this map using both our explicit series expansion construction of Coherent States , Wavelets, as well as using Group Theoretic methods. At some point (maybe part 17 of this blog) I will try to get Coherent states that appear in Affine Quantum Gravity, in Loop Quantum Gravity, and in String Theory. More importantly, for understanding machine learning, we will see the mathematical formulation of Frame Quantization and the attempts to capture the mathematics of coherent states under a single mathematical formalism (and how and when this is doable) . Please stay tuned , ask questions, and post comments.

Good work Chuck!
LikeLike
Thanks man!
It is hard to write pedagogically. Plus the WordPress Latex interface is great to have although it gets confused a lot (a lot!). If I can get WordPress to behave I will produce some new ideas too 😛
LikeLike