In the next few posts, I am going to discuss how to use the generalization metrics included in the open-source weightwatcher tool. The goal is to develop a general-purpose tool can that you can use, among other things, to predict (tends in) the test accuracy of a Deep Neural Network — without access to the test data — or even training data!
WeightWatcher is a work in progress, based on research into Why Deep Learning Works, and has been featured in venures like ICML, KDD, JMLR and Nature Communications.
Before we start, let me just say that it is very difficult to develop general-purpose metrics that can work for any arbitrary DNN (DNN), and, also, maintains a tool that is also back comparable with all of our work to be 100% reproducible. I hope the tool is useful to you, and we rely upon your feedback (positive and negative ) to improve the tool. so if it works for you, please let me. If not, feel free to post an issue on the Github site. Thanks again for the interest!
Given this, the first metrics we will look at will be the
Random Distance Metrics
How is it even possible to predict the generalization accuracy of a DNN without even needing the test data ? Or at least trends ? The basic idea is simple; for each later weight matrix, measure how non-random it is. After all, the more information the layer learns, the less random it should be.
What are some choices for such a layer capacity metric:

- Matrix Entropy:
- Distance from the initial weight matrix:
(and variants of this)
- DIvergence from the ESD of the randomized weight matrix:

![div[\mathbf{W}, \mathbf{W}_{rand}]](https://s0.wp.com/latex.php?latex=div%5B%5Cmathbf%7BW%7D%2C+%5Cmathbf%7BW%7D_%7Brand%7D%5D&bg=ffffff&fg=%23000000&s=0&c=20201002)
Matrix Entropy
We define 
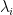
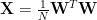
So the matrix entropy i is both a measure of layer randomness and a measure of correlation.
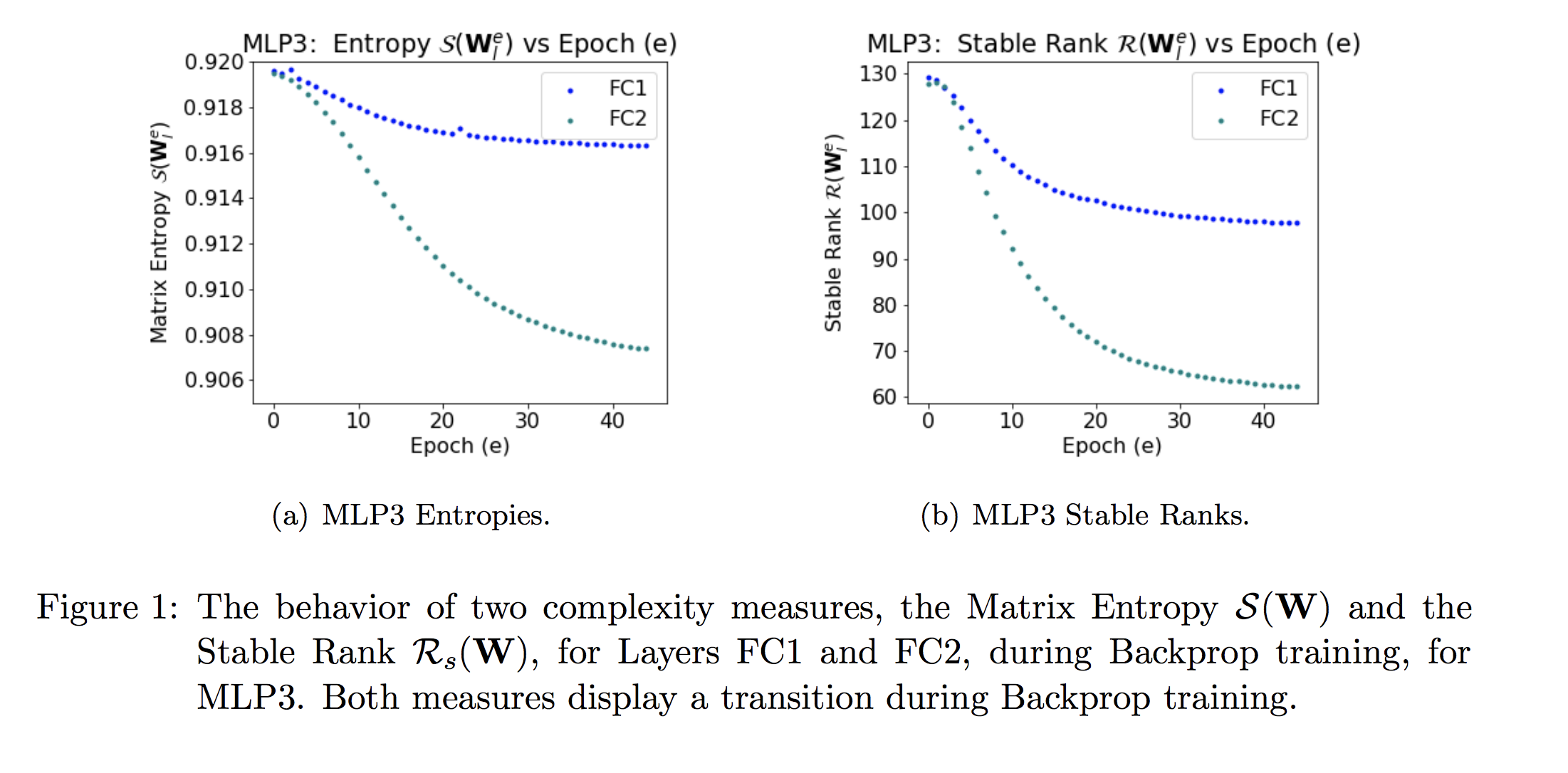
In our JMLR paper, however, we show that while the Matrix Entropy does decrease during training, it is not particularly informative. Still, I mention it here for completeness. (And in the next post, I will discuss the Stable Rank; stay tuned)
Distance from Init:
The next metric to consider is the Frobenius norm of the difference between the layer weight matrix 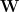

The weightwatcher tool supports this metric with the distance method:
import weightwatcher as ww watcher = ww.watcher(model=your_model) <strong>distance_from_init</strong> = watcher.distances(your_model, init_model)
where init_model is your model, with the original, actual, initial weight matrices.
In our most recent paper, we evaluated the distance_from_init method as a generalization metric in great detal, however, in order to cut the paper down to submit (which I really hate doing), we had to remove most of this discussion, and only a table in the appendix remained. I may redo this paper, and revert it to the long form, at some point. For now, I will just present some results from that study here, that are unpublished.
These are the raw results for the task1 and task2 sets of models, described in the paper. Breifly we were given about 100 pretrained models, group into 2 tasks (corresponding to 2 different architectures), and then subgrouped again (by the number of layers in each set). Here, we see how the distance_from_init metric correlates against the given test accuracies–and it’s pretty good most of the time. But’s not the best metric in general.


The are a few variants of this distance metric, depending on how one defines the distance. These include:
- Frobenius norm distance.
- Cosine distance
- CKA distance
Currently, weightwatcher 0.5.5 only supports (1), but in the next minor release, we plan to include both (2) & (3).
The problem with this simple approach is it is not going to be useful if your models are overfit because the distance from init increases over time anyway–and this is exactly what we think is happening in the task1 models from this NeurIPS contest. But it is a good sanity check on your models during training, and can be used with other metrics as a diagnostic indicator.
So the question becomes, can we somehow create a distance-from-random metric that compensates for overfitting. And that leads to…
Distance from Random: (rand_distance)
With the new rand_distance metric, we mean something very different from the distance_from_init. Above, we used the original instantiation of the 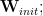
- Does not require the original, initial weight matrics
- Is not an element-wise metric, but, instead, is a distributional metric
So this metric is defined in terms of a distance between the distributions of the eigenvalues (i..e the ESDs) of the layer matrix 
For weightwatcher, we choose to use the Jensen-Shannon divergence for this:
rand_distance = jensen_shannon_distance(esd, random_esd)
where
def jensen_shannon_distance(p, q):
m = (p + q) / 2
divergence = (sp.stats.entropy(p, m) + sp.stats.entropy(q, m)) / 2
distance = np.sqrt(divergence)
return distance
Moreover, there are 2 ways to construct the random layer matrix $\mathbf{W}_{rand}&bg=ffffff$ metric:
- Take any (Gaussian) Random Matrix, with the same aspect ratio
as the layer weight matrix
- Permute (shuffle) the elements of
While at first glance, these may seem the same, in fact, in practice, they can be quite different. This is because while every (Normal) Random Matrix has the same ESD (up to finite size effects), the Marchenko-Pastur (MP) distribution, if the actual 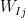
Indeed, when
The take-a-way here is that, when a layer is well trained, we expect the ESD of the layer to be significantly different from the ESD its randomized, shuffled form. Let’s compare 2 cases:
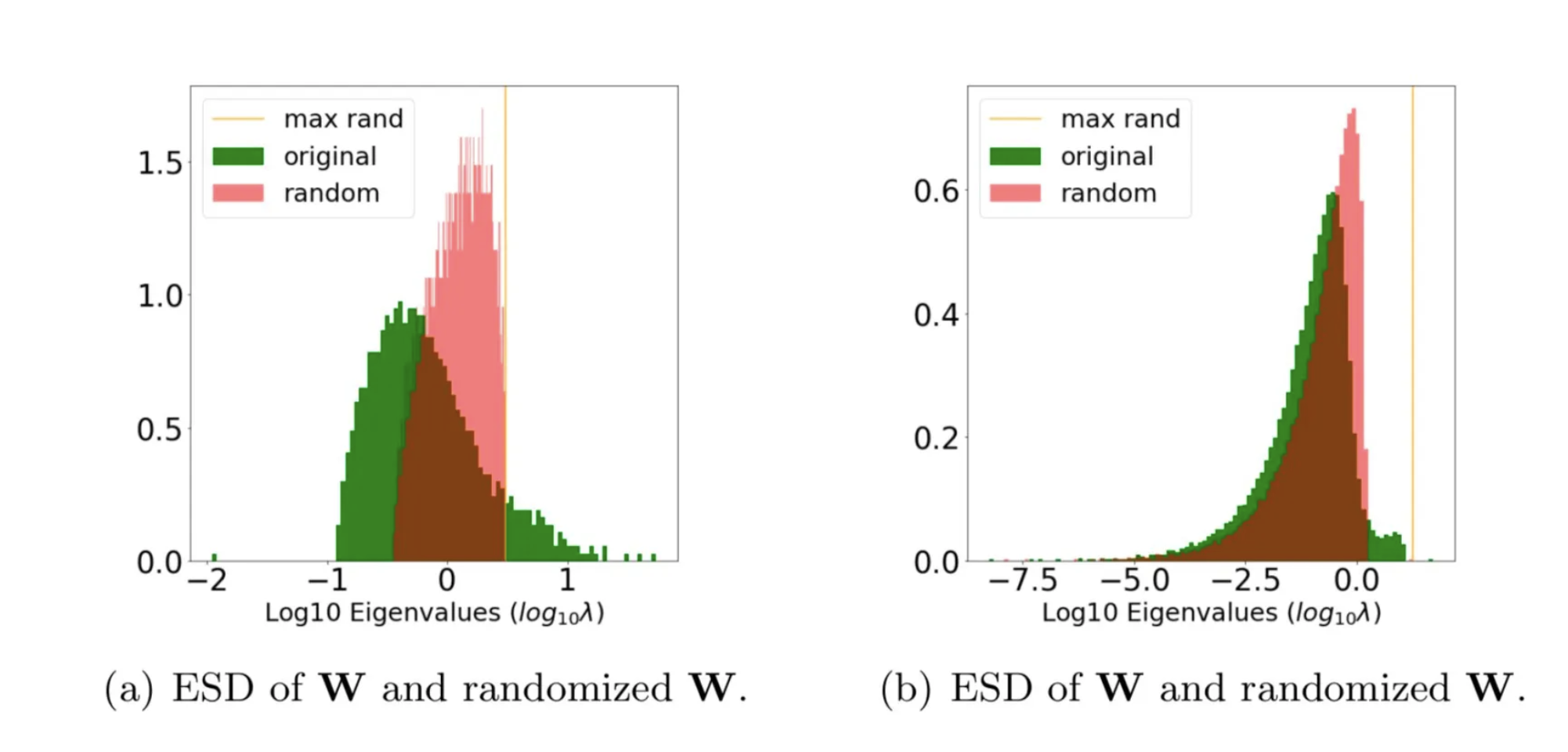
The rand_distance metric measure the divergence between the original and random ESDs
In case (a), the original ESD (green) looks significantly different from its randomized ESD (red). In case (b), however, the original the randomized ESDs are much more similar. So we expect case (a) to be more well trained than case (b).
And rand_distance works, presumably, at least in some cases, when the layer is overtrained, as in (b).
To compute the rand_distance metric, simply specify the randomize=True option, and it will be available as a layer metric in the details dataframe
import weightwatcher as ww watcher = ww.watcher(model=your_model) details = watcher.analyze(randomize=True) avg_rand_distance = details.rand_distance.mean()
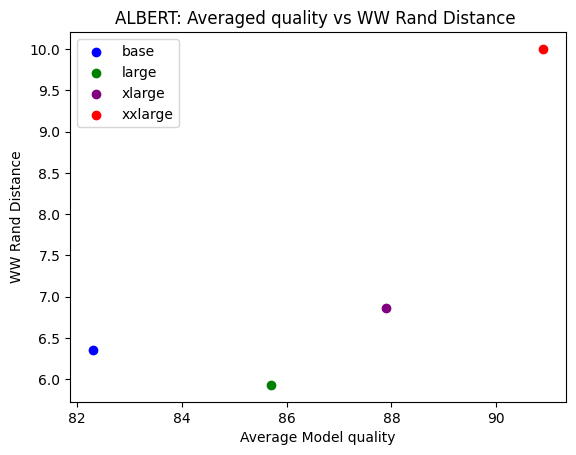
Finally, let’s see how well the rand_distance metric actually works to predict trends in the test accuracy for a well known set of pretrained models, the ALBERT series. Similar to the analysis in our Nature paper, we consider how well the average rand_distance metric is correlated with the reported top1 errors of the series of ALBERT models: base, large, xlarge, xxlarge
I’ll end part 1 of this series of blog posts with a comparison between the new rand_distance metric and the weighwatcher alpha metric, for another well known model: VGG19
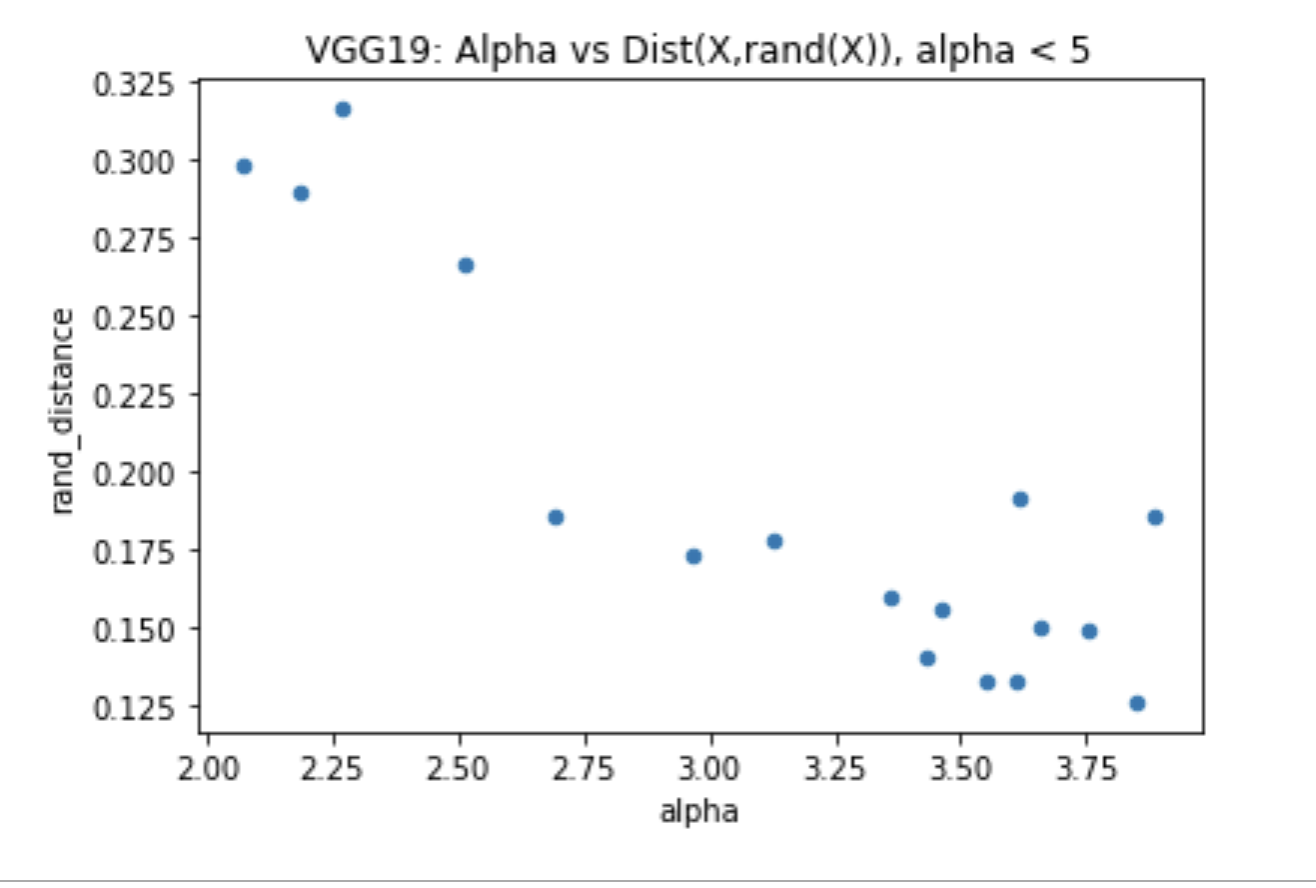
When the weightwatcher alpha < 5, this means that the layers are Heavy Tailed and therefore well trained, and, as expected, alpha is correlated with the rand_distance metric. As expected!
I hope this has been useful to you and that you will try out the weightwather tool
pip install weightwatcher
Give it a try. And please give me feedback if it is useful. And, if interested in getting involved or just learning more, ping me to join our Slack channel. And if you need help with AI, reach out. #talkToChuck #theAIguy
