Why are SVMs interesting? It is just a better way to do Logistic Regression? Is it the Kernel Trick? And does this even matter now that Deep Learning is everywhere? To the beginning student of machine learning, SVMs are the first example of a Convex Optimization method. To the advanced practitioner, SVMs are the starting point to creating powerful Convex Relaxations to hard problems.
Historically, convex optimization was seen as the path to central planing an entire economy. A great new book, Red Plenty, is “about the scientists who did their genuinely brilliant best to make the dream come true …” [amazon review].
It was a mass delusion over the simplex method, and it is about as crazy as our current fears over Deep Learning and AI.
Convex optimization is pretty useful, as long as we don’t get crazy about it.
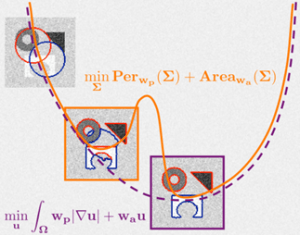
The prototypical method convex relaxation is for Transductive Learning and the Transductive SVM (TSVM)
Vapnik proposed the idea of Transduction many years ago; indeed the VC theory is proven using Transduction. I would bet that he knew a TSVM could be convexified–although I would need a job at Facebook to verify this.
A good TSVM has been available since 2001 in SvmLight, But SvmLight is not opensource, so most people use SvmLin.
Today there are Transductive variants of Random Forests, Regression, and even Deep Learning. There was even a recent Kaggle Contest–the Black Box Challenge (and, of course, the Deep Learning method won). Indeed, Deep Learning classifiers may benefit greatly from Transductive/SemiSupervised pretraining with methods like Pseudo Label [8], as shown in the Kaggle The National Data Science Bowl contest.
We mostly care about binary text classification, although there is plenty of research in convex relaxation for multiclass transduction, computer vision, etc.
Transductive learning is essentially like running a SVM, but having to guess a lot of the labels. The optimization problem is

where 

and the binary labels 
The optimization is a non-convex, mixed-integer problem. Amazingly, we can reformulate the TSVM to obtain a convex optimization!
This is called a Convex Relaxation, and it lets us guess the unknown labels…
to within a good approximation, and using some prior knowledge.
Proving an approximation is truly convex is pretty hard stuff, but the basic idea is very simple. We just want to find a convex approximation to a non-convex function.
It has been known for a while that the TSVM problem can be convexified [5]. But it has been computationally intractable and there is no widely available code.
We examine a new Convex Relaxation of the Transductive Learning called the Weakly Labeled SVM (WellSVM) [2,3].
In the Transductive SVM (TSVM) approach, one selects solutions with minimum SVM Loss (or Slack)
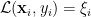
and the maximum margin

The SVM Dual Problem
Let us consider the standard SVM optimization

which has the dual form

To keep the notation simpler, we will not consider the Kernalized form of the algorithm. Besides, we are mostly interested in text classification, and Kernels are not needed.
Balancing the Labels
In a TSVM, we have to guess the labels 
we need to constrain the label configurations by balancing the guesses

We assume that we have some idea of the total fraction of positive (+) labels
- Perhaps we can sample them?
- Perhaps we have some external source of information.
- Perhaps we can estimate it.
This is, however, a critical piece of prior information we need. We define the space of possible labels as

i.e, for exactly half positive / negative labels, then

and the true mean label value is zero

So we are saying that if we know
- the true fraction
of (+) labels
- some small set of the true labels (i.e. < 5%)
- the features (i.e. bag-of-words for text classification)
Then we know almost all the labels exactly! And that is powerful.
Note: it is critical that in any transductive method, we reduce the size of the label configuration space. The Balancing constraint is the standard constraint–but it may be hard to implement in practice.
Convex Methods
The popular SvmLin method use a kind of Transductive Meta-Heuristics that set the standard for other approaches. The problem is, we never really know if we have the best solution. And it is not easy to extend to multiclass classification.
Convex methods have been the method of choice since Dantzig popularized the simplex method in 1950

Although linear programming itself was actually invented in 1939 by Leonid Kantorovich [7] — “the only Soviet scholar ever to win the Nobel Prize for Economics”
A convex method lends itself to production code that anyone can run.
The WellSVM Convex Relaxation
More generally, we need to solve a non-convex min-max problem of the form

where the G matrix is
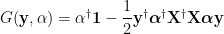
where α lies in the convex set

Notice that G is concave in α and (can be made) linear in the y’s [3]. We seek a convex relaxation of this min-max problem. And, as importantly, we want to code the final problem using an off-the-shelf SVM solver with some simple mods. The steps are
1 . Apply the Minimax Theorem
 For details, see [4,5], although it was originally posed by John von Neumann in his work on Game Theory.
For details, see [4,5], although it was originally posed by John von Neumann in his work on Game Theory.
One could spend a lifetime stuyding von Neumann’s contributions. Quantum mechanics. Nuclear Physics. Etc.
Here we scratch the surface.
The Minimax thereom lets us switch the order of the min/max bounds.

The original problem is an upper bound to this. That is

To solve this, we
2. dualize the inner minimization (in the space of allowable labels)
We convert the search over possible label configurations into the dual max problem, so that the label configurations become constraints.

This linear in α and θ. In fact, it is convex.
There are an exponential number of constraints in 

Even though it is convex, we can not solve this exactly practice. And that’s…ok.
Not all possible labelings matter, so not all of these constraints are active (necessary) for an optimal solution.
We just need an active subset, 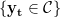
The Cutting Plane, or Gomory Chvatal, method. (Remember, if you want to sound cool, give your method a Russian name).
To proceed, we construct the Lagrangian and then solve the convex dual problem.
You may remember the method of Lagrange multipliers from freshman calculus:

3. We introduce Lagrange Multipliers for each label configuration
The Lagrangian is

When we set the derivative w.r.t. 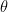
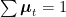
This lets us rewrite the TSVM as

where the set of allowable multiplers 
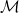
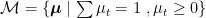
The resulting optimization is convex in µ and concave in α.
This is critical as it makes a Kernel-TSVM a Multiple Kernel Learning (MKL) method.
“WellSVM maximizes the margin by generating the most violated label vectors iteratively, and then combines them via efficient multiple kernel learning techniques”.
For linear applications, we need only consider 1 set of
Now replace the inner optimization subproblem with its dual. Of course, the dual problem is a lower bound on the optimal value. We then
4. switch the order of the min/max bounds back
to obtain a new min-max optimization–a convex relaxation of the original

When we restrict the label configurations to the working set

Implementation Details
A key insight of WellSVM is that the core label search

is equivalent to

To me, this is very elegant!
 We search the convex hull of the document-document density matrix, weighted by the Langrange multipliers for the labels.
We search the convex hull of the document-document density matrix, weighted by the Langrange multipliers for the labels.
How can we solve a SVM with exponential constraints? Take a page from old-school Joachim’s Structural SVMs [6].
Cutting Plane Algorithm for WellSVM
This is the goto-method for all Mixed Integer Linear Programming (MILP) problems. On each iteration, we
- obtain the Lagrange Multipliers
with an off-the-shelf SVM solver
- find a violating constraint (label configuration)
This grows the active set of label configurations 
the PseudoCode is
- Initialize
and
- repeat
- Update
- Obtain the optimal α from a dual SVM solver
- Generate a violated
- until



Finding Violated Constraints

The cutting plane algo finds a new constraint, or cuts, on each iteration, to ‘chip away’ at a problem until the inner convex hull is found. It usually finds the most violated constraint on each iteration, however,
With SVMs we can get good results just finding any violated constraint.
Here, we seek 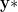
For any violation 

where

This lets us compute
First, compute 

Second, compute

References
[1] The Semi-Supervised Learning Book (2006)
[2] Convex and Scalable Weakly Labeled SVMs , JMLR (2013)
[3] Learning from Weakly Labeled Data (2013)
[4] Kim and Boyd, A Minimax Theorem with Applications to Machine Learning, Signal Processing, and Finance, 2007
[5] Minimax theorem, game theory and Lagrange duality
[6] Cutting-Plane Training of Structural SVMs
[7] “This is an example of Stigler’s law of eponymy, which says that “no scientific discovery is named after its original discoverer.” Stigler’s law of eponymy is itself an example of Stigler’s law of eponymy, since Robert Merton formulated similar ideas much earlier Quote from Joe Blitzstein on Quora
[8] Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks

Hi Charles,
very nice piece of information!
Where one can find original matlab code for learning for WellSVM Relaxation?
LikeLike
http://lamda.nju.edu.cn/Default.aspx
LikeLike