SVMs are great for building text classifiers–if you have a set of very high quality, labeled documents.
Frequently, we just don’t have enough labelled data! What can we do?
- We can crawl the web for more labelled data. For this purpose, here at Calculation Consulting we built a production quality crawler
- Pay mechanical Turks to label the documents. This is actually harder than it sounds.
- We can use what labels we have, and try to guess the labels of the unlabeled documents.
Guessing labels is called Transductive Learning and is the topic of this post.
SVMs and Self-Training
We have a huge collection of documents, perhaps with just a few labels. The obvious, or perhaps naive, thing to do is build a classifier using what we have, and then try to scale it out incrementally by self-training. That is, we select documents labeled that are labelled high confidence by the smaller model and use them to build a training data set for a larger SVM model:

So this seems pretty simple — what could go wrong? Since the initial model has very little labeled data, it is going to make lots of mistakes, even in the high confidence regime. We are adding in some data that is mis-labeled. As we incrementally self- train, we amplify these errors, thereby reducing overall accuracy. So what can be done?
Transductive Learning
Suppose that, as we add the new data in, instead of just naively using our smaller model to label the new data, we could automatically somehow switch the labels on these new documents, and then pick the best model from all these possibilities. That is, we run an SVM where we retain the labels on the labeled (blue) documents, but we let the labels on the test (purple) documents float. We constrain the problem so that at least 
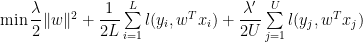
subject to the constraint
![\dfrac{1}{U}\sum\limits_{j=1}^{U}\max[0,sign(w^{T}x_{j}')]=r](https://s0.wp.com/latex.php?latex=%5Cdfrac%7B1%7D%7BU%7D%5Csum%5Climits_%7Bj%3D1%7D%5E%7BU%7D%5Cmax%5B0%2Csign%28w%5E%7BT%7Dx_%7Bj%7D%27%29%5D%3Dr+&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
where the 
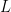

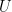
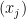
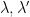
Why does Adding Test Data to the Training Set Improve the Accuracy?
When we don’t have enough training data, the SVM optimization problem is still convex, but the optimal solution may be spurious. Imagine that we are trying to train a binary text classifier with only say 100 documents in each class. The classifier will learn how to separate the documents, but it will not be able to generalize to new documents because it simply has not seen enough examples or really enough words to build a usable feature space. The solutions may be spurios.
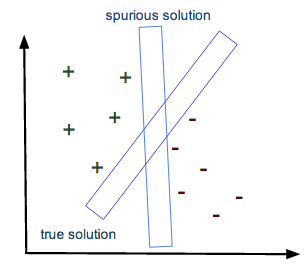 Indeed, there may exists many margins that separate the data, and the largest may not be the one that generalizes best. That is, without enough training data, the SVM may mis-learn and think that noise words are driving the classification.
Indeed, there may exists many margins that separate the data, and the largest may not be the one that generalizes best. That is, without enough training data, the SVM may mis-learn and think that noise words are driving the classification.
We want is a classifier that generalizes to unseen test documents;
if we don’t have test labels, perhaps we can guess them.
When we add unlabeled documents , or test data (circles) , to the classifier training data. If we can guess the labels of the circles correctly, we can find the optimal solution because it is less ambiguous:
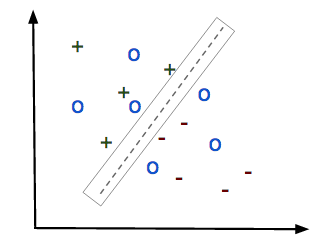
Notice that since we are seeking a maximum margin solution, we implicitly are assuming that the documents form clusters in feature space because the margin lives in the low density regime between document clusters. We are also are increasing the size of feature space, thereby greatly improving the generalizabilty of the model.
TSVM Algorithm: Deterministic Annealing
Unlike a standard (inductive) SVM, the TSVM optimization problem is highly non-convex and quite difficult to solve exactly. Clearly we can not switch the labels on all the new documents; if we add in N documents, then we have 
There are several known approaches to solving the TSVM–both of which are readily available in the open source package SvmLin:
- Label Switching Heuristics (-A 2) , and
- Deterministic Annealing (-A 3)
We will discuss the Deterministic Annealing (DA) algorithm because it is very nice example of how to combine the ideas of SVMs with the techniques of Statistical Mechanics discussed in our last post. Other, more modern Transductive learning algos may use alternate methods such as convex-concave programming (CCCP, available in Universvm [11]) , and even quasi-Newton gradient descent (QN-S3VM) [10].
In the original paper [3], TSVM refers to option -A 2, and DA to -A 3. Here, we use the term TSVM to mean any implementation (TSVM, DA, CCCP, QN-S3VM). Because we are applying the TSVM to text, however, we do not advocate using label propagation or other graph based methods.
Combining SVMs with Statistical Mechanics
We previously, discussed basic Statistical Mechanics and Simulated Annealing, where we derive the concept of Entropy.
To solve the TSVM / DA optimization problem, we need relax the constraint on the labels that they be integers, and, instead let them represent the probability of being in the (+) or (-) class. We then introduce a temperature 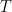
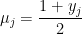
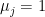
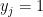
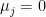

This lets us re-write the TSVM optimization problem as
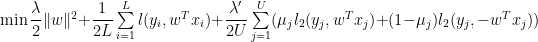
where we write 
We now take a trick from the Ising model in Statistical Mechanics. We want to transform the labels
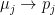
into probabilities that range from 0 to 1:
![p_{j}\in[1,0]](https://s0.wp.com/latex.php?latex=p_%7Bj%7D%5Cin%5B1%2C0%5D+&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
and are normalized to the total number of expected positively labeled instances:
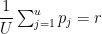
How do we incorporate probabilities into our SVM optimization problem? We are already selecting the maximum margin of the training data; we now need to also select the optimal probabilities — the minimum Entropy — of the labels for the unlabeled data.
We extend the TSVM max-margin problem, adding a term that maximizes the total Entropy 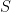
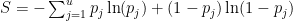
Actually, since we minimize 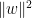
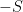
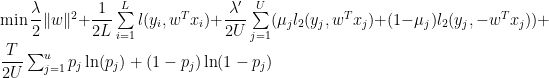
where the additional parameter
Handing this constraint is a bit more complicated, and we refer to [3]; we do note that the constraint can be re-written into what looks like a Fermi energy, which is quite interesting.
We maximize the Margin on the training (and test) sets,
and minimize the Entropy on the test set.
Solving this optimization problem requires alternating between solving the labeled SVM optimization problem (maximizing the margin 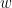
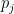
We also need to be careful not to overtrain. So I will select out the newly labeled data with the highest confidence labels and then use this as training data for the production SVM (i.e LibLinear). This would allow the data scientist to then take a label set of say 100 documents per class, and automatically extend it to say 10,000 labeled documents per class without the use of mechanical Turks or crawling the web.
Despite the wonderful advantages promised by Transductive (and SemiSupervised) Learning, it is quite hard to apply in practice and has not achieved even close to the popularity of its Supervised and Unsupervised counterparts. TSVMs need both proper tuning [8] and well designed data sets. We need to understand it’s practical implementation much better to use it.
Practical Issues: Selecting the best labelled data
An initial training data set may be naively separable if it is small and has a large number of features :
naively separable:
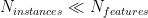
As a data set grows, we may have far more instances than features:
 potentially unseparable:
potentially unseparable:
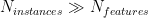
which makes it far more probable that some instances will lie in the slack region between classes.
We usually run a tool like LibLinear , which implements either a soft-margin SVM or L2-regularized Logistic Regression. Indeed, in practice is usually impossible to tell the difference between these 2 models. The additional slack terms can be though of as an extended regularizer or as modifying the SVM loss function. Indeed, even Vapnik himself has argued that it can be very beneficial to run an SVM with a large number of adjustable slack variables (i.e in master learning and/or his universum model [5]). The SvmLin implementation of the TSVM is a hard margin (binary, no slack variables) SVM, but it does use the L2-SVM loss function (and not the harder hinge loss).
It is suggested to run the TSVM slowly and repeatedly to relabel documents, and, on each iteration, to only take new labels that have moderately high confidence (and therefore, hopefully, outside the slack region).
Of course, there is always the risk of biasing the data set, and it may be better to augment the selection process by selecting documents that are high confidence and close. For example, in the S4VM approach, they high confidence documents that are also close to the labeled documents, as determined through a hierarchal clustering method.
In between each stage, it would be useful to apply a mechanical turk to check the results to ensure the newly labelled data is not bananas.
Practical Issues: designing multiple 1-vs-1 data sets
Additionally, SvmLin only implements a binary SVM, whereas many practical applications require a multi-class SVM. More generally, one might try to extend the TSVM to a DA type algorithm using say a Potts model–a classic model in physics that generalizes an Ising model. MultiClass Transductive Learning is a topic of current research. For now we have to use SvmLin or a related package (Universvm, QN-S3VM) to get practical solutions.
In a normal SVM, balancing the class data is important; in a Transducitve-SVM, it is absolutely critical. For example, this recent study on TSVMs discussed the issue. This can be quite challenging in real world, production environments, and if you want to apply this powerful technique, extra care should be taken to design the TSVM (training + test) sets.
To apply SvmLin, it is necessary to carefully construct a collection of 1-vs-1 binary SVMs; current TSVMs don’t work for 1-vs-all data sets [4]
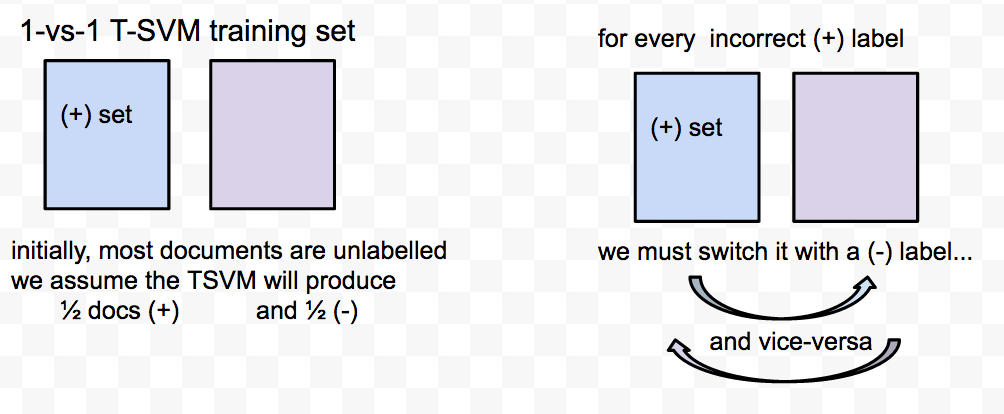
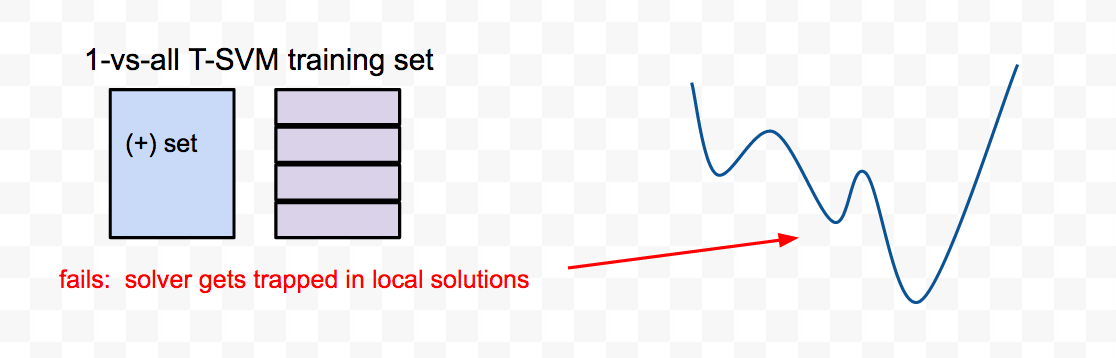
For example, suppose we have a 4 class model, but we only have a few labeled instances for each class. If we try to extend the set of instances for class 1, we need to carefully construct four 1-vs-1 binary TSVMs, and not one large data set for a 1-vs-all binary TSVM. Each individual binary TSVM classifier should be designed carefully so that each class (+/-) consists of a single kind of document;. Otherwise the solver will get trapped in a local solution and the TSVM will be worse.
Furthermore, the fraction 
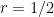
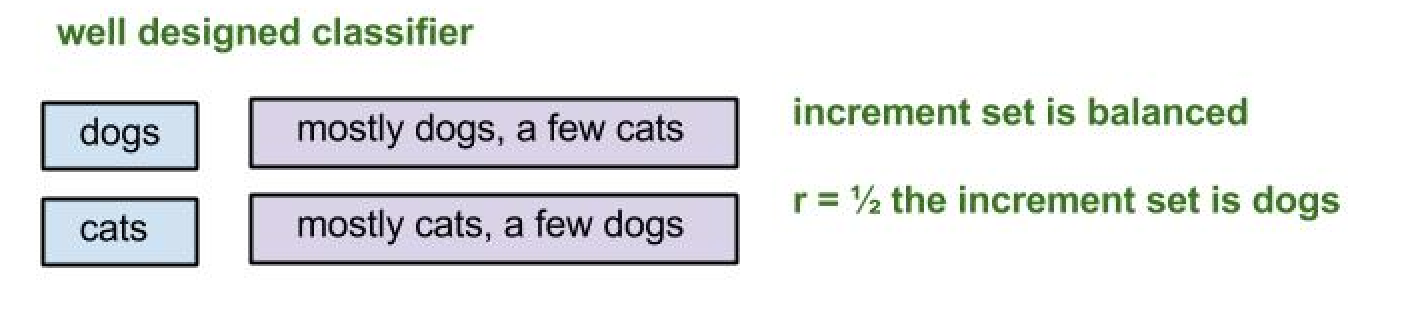
The TSVM can help add labeled data to a well designed model; it can not be used to repair a poorly designed classification model .
Consider a binary SVM trained on a small training set of cat and dog videos. We then apply the model to some unseen test videos, and select a large number of videos that were labelled either cats or dogs. The model will certainly make mistakes, but we can hope that the errors are balanced across both classes. So when we apply the TSVM to the entire training + test set, half of the data will still actually be dog videos.
On the other hand, let’s consider the poorly designed classifier shown below. Here, we have 3 classes: dogs, cats, and animals. The third class is trained for animal videos, and may contain dogs, cats, horses, mice, etc. This is a bad design, and we would see this, say, in the confusion matrix for the entire model. Even if we create three 1-vs-1 TSVMs, we are not going to get anywhere. When we create the increment set, to train the TSVM, we have no idea what fraction of the training + test set are actually dog videos. So we can not really fix the normalization constraint
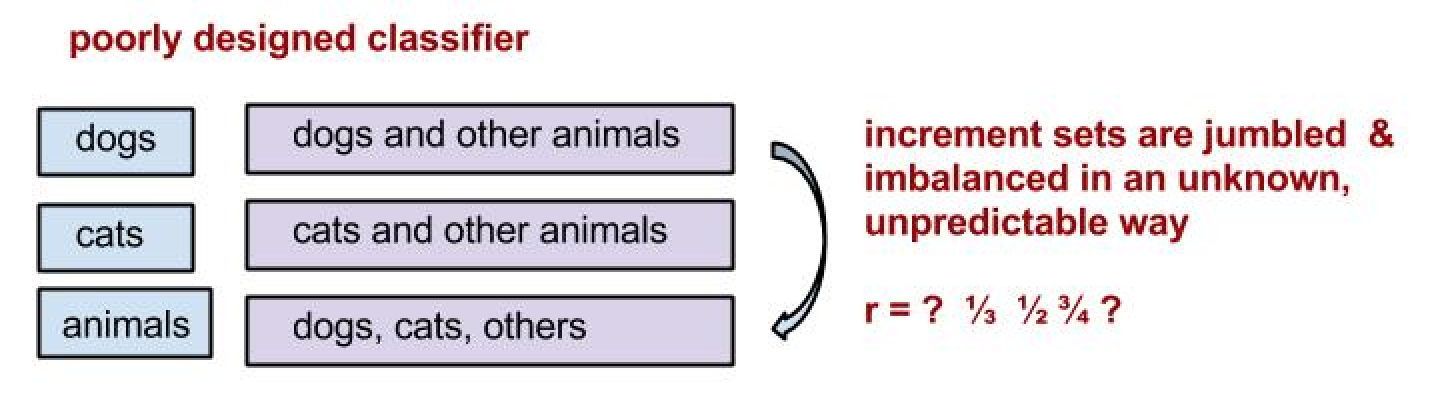
Furthermore, the animals category will likely consist of a number a document clusters (dog, cat, horse, mouse, ferret, etc) and the TSVM solver will not converge properly for say the dog/animals binary TSVM. The multiple clusters may confuse the solver (although since this may be an artifact of the DA algorithm getting trapped in local minima and not an inherent problem in the theory)

Ideally, each (+/-) class must effectively capture a single, simple text cluster.
Epilogue
Transductive Learning was first proposed by more than thirty years ago by Vapnik and Chervonenkis [6] , and it is a critical idea in the development of the famous VC Theory of Statistical Learning [1]. In a future post, we will look in detail at the role of Transductive Inference in the VC theory and some other formulations such as the UniverSVM and Instance Weighted SVMs [6].
Practically, there are few useful Transductive and Semi-Supervised ML algos to use :
- the SvmLin open source code , which we use and discuss here
- Joachim’s SVMLight , the first high performance TSVM implementations, but it is not open source
- the very recent QN-S3VM package, available in python [10]
- the TSVM in the UniverSVM package [11]
also note
- The famous scikit-learn package has 1 method, a semi-supervised Label Propagation algorithm. but this is not suitable for text
- It appears the enterprise tool RapidMiner does implement a commercial version of a TSVM, although I personally have not tried it.
In our next post, we will run some experiments with the SvmLin code and see how well it works on some real world datasets.
At some point in the futurem we wlll discuss [12] and what (we think) is going on at Google Deep Mind.
To get involved, goto https://github.com/CalculatedContent/tsvm
References
[1] Vladimir Vapnik. Statistical learning theory. Wiley, 1998. ISBN 978-0-471-03003-4.
[2] T. Joachims, Transductive Inference for Text Classification using Support Vector Machines, ICML 1998
[3] V. Sindhwani, S. Sathiya Keerthi, Large Scale Semi-supervised Linear SVMs, 2006
[4] O. Chapelle, B. Scholkopf, A. Zien, Semi-Supervised Learning, 2006
[5] http://www.cs.princeton.edu/courses/archive/spring13/cos511/handouts/vapnik-slides.pdf
[6] Vapnik, V., & Chervonenkis, A. The Theory of Pattern Recognition, Moscow 1974
[7] Ran El-Yaniv, Dmitry Pechyony, Transductive Rademacher Complexity and its Applications
[8] J. Wang, X. Shen, W. Pan On Transductive Support Vector Machines
[9] C. Yu , Transductive Learning of Structural SVMs via Prior Knowledge Constraints
[10] Fabian Gieseke, Antti Airola, Tapio Pahikkala, and Oliver Kramer. Fast and Simple Gradient-Based Optimization for Semi-Supervised Support Vector Machines, Neurocomputing (ICPRAM 2012 Special Issue), Elsevier, accepted; Fabian Gieseke, Antti Airola, Tapio Pahikkala, and Oliver Kramer. Sparse Quasi-Newton Optimization for Semi-Supervised Support Vector Machines, Proceedings of the 1st International Conference on Pattern Recognition Applications and Methods (ICPRAM 2012), pages 45-54, 2012. [pdf]
[11] Ronan Collobert ,Fabian Sinz Jason Weston Leon Bottou, Large Scale Transductive SVMs Journal of Machine Learning Research 7 (2006)
[12] Semi-supervised Learning with Deep Generative Models at Google Deep Mind

Thanks for this interesting post, Charles. Does restricting the hyperplanes to pass through the origin often limit performance?
LikeLike
ok ill try it on some datasets
on the libsvm a1a.t dataset, i find
liblinear-1.94/train -v 10 a1a.t
Cross Validation Accuracy = 84.8785%
liblinear-1.94/train -v 10 -B 1 a1a.t
Cross Validation Accuracy = 84.8688%
if we do a quick grid search we can get slightly better results
1 84.8688%
2 84.8333%
3 84.885%
4 84.8979%
5 84.8785%
6 84.8915%
7 84.8753%
8 84.8495%
9 84.9108%
10 84.9141%
LikeLike
Do you have a twitter account which I can follow?
LikeLike
LikeLike
Thank you for this useful article
LikeLike
Please @charlesmartin14, can you pls give me the list of Tools/Packages that have full implementation of TSVM? do you know anything about Transferred Discriminative Analysis (TDA) algorithm? It can be used for dimensionality reduction in a transfer learning domain? I need some information about the algorithm. Thanks.
LikeLike
I dont know TDA but we can take a look if you like. TSVM is available in SvmLin as standalone Unix code, and is available in python as QN-S3VM. See my later blog posts
https://charlesmartin14.wordpress.com/2014/11/01/machine-learning-with-missing-labels-part-3-experiments/
LikeLike
also remember to make these methods work you need to be able to estimate R = fraction of positively labelled examples.
LikeLike
Thank you so much Charles. You can download the article below on TDA and explore. After exploring, can we say that TDA can do the work of TSVM and more? Thanks
Transferred Dimensionality Reduction by
Zheng Wang,Yangqiu Song and Changshui Zhang
State Key Laboratory on Intelligent Technology and Systems Tsinghua National Laboratory for Information Science and Technology (TNList) Department of Automation, Tsinghua University, Beijing 100084, China
LikeLike
To use these methods it is necessary to estimate R. This can be done by sampling the labeled data you have, by estimating R using external information, by using a kernel estimation methods, or by trying various values of R and then testing the quality of the resulting labels
Essentially, we can consider the TSVM as guessing the unknown labels and is therefore an unsupervised clustering method. To that end, we can select the best R by using a metric that selects the best clusters given a labeling, such as the silhouette score.
LikeLike