This post is still just sketch of ideas…not ready for consumption
In my last post I introduced the Eigenvalue-Dependent Effective (Semantic) Operator as a Semantic Similarity metric that couples visible (P) and hidden (Q) features:

where 

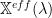
It is necessary, however, to solve find the dominant eigenvalue of
We now introduce the Eigenvalue-Independent Effective (Semantic) Operator , using techniques from quantum mechanical many body perturbation theory (MBPT), that resolves all of these issues.
The Correlation Operator
Consider again the eigenvalue equation for the feature correlation matrix
![[\begin{array}{cc} P\mathbb{X}P & P\mathbb{X}Q\\ Q\mathbb{X}P & Q\mathbb{X}Q \end{array}]\begin{array}{c} Px\\ Qx \end{array}= \lambda\begin{array}{c} Px\\ Qx \end{array}](https://s0.wp.com/latex.php?latex=%5B%5Cbegin%7Barray%7D%7Bcc%7D++++P%5Cmathbb%7BX%7DP+%26+P%5Cmathbb%7BX%7DQ%5C%5C++++Q%5Cmathbb%7BX%7DP+%26+Q%5Cmathbb%7BX%7DQ++++%5Cend%7Barray%7D%5D%5Cbegin%7Barray%7D%7Bc%7D++++Px%5C%5C++++Qx++++%5Cend%7Barray%7D%3D+%5Clambda%5Cbegin%7Barray%7D%7Bc%7D++++Px%5C%5C++++Qx++++%5Cend%7Barray%7D++++&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
We now re-write this using subscripts, and identify the expressions for the P and Q space

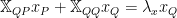
Recall before we formed an explicit expression for 
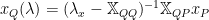
Fet us define a new operator, 
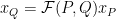
Our goal can be restated as to find a suitable Correlation Operator
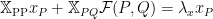

using the definition of $latex \mathcal{F}(P,Q) $, multiply the R.H.S. of (4) by this to obtain

Subtracting equation (5) and (6) to into a single equation

Our goal is then to find
In particular, we do not seek an exact Effective Operator since , usually in Machine Learning, our input data is noisy and may only have a few significant figures. Indeed, we expect that an approximate Effective Operator will perform better than the exact solution. Also, we may want to add a regularizer, and we will need a formalism that permits this.
Our Effective Operator will take the form
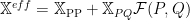
but this operator may not be Hermertian– a requirement for a Machine Learning Kernel. We can, however, in certain cases, form the associated Hermetian effective operator by taking the sum of 

Finally, we are not really trying to model an eigenvalue problem but rather the (semantic) feature-feature similarities. Consequently, we will need a formalism that lets us treats features explicitly, and does not just model the eigenvalues and eigenvectors of
So how do we get here? While the final result is quite simple, the road to get there is long and technical.
Notation: Primitive Features and Hilbert Spaces
Lower case letters (p) refers to primitive features like tags 
We refer to the space of features 

In physics and chemistry,
The spaces 

Identifying Primary Features
Let us consider in more detail how we define our features spaces 
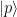

the p-space weights $latex w_{p} $ are much larger than the q-space weights

$latex w_{p}\gg w_{q} $
More importantly, lets consider how the Eigenvalues of

Here I sketch the possible eigenvalues of the feature density matrix
It is precisely this distinction among features — the ability to identify a dominate class of features — that allows us to apply the Effective Operator technique. In some cases, this will be self-evident. In others, it might seem fictitious since we decided beforehand how to construct the feature density matrix
The Complete Model / Feature Space
Let’s consider how we might identify a model space 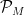
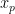

We do not know yet what the P-space actually is. We might try to pick it using an SVD/LSA approach–we simply pick the N lowest eigenvectors of 

Since we don’t know it, we will guess. We model the true P-space eigenfunctions by the space of functions 
$latex \mathcal{P}_{M}\sim P^{t}\mathbb{X}P $
We write the model primary and secondary space projection operators as
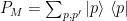
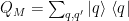
We call the model space 
Indeed, we are , in the most literal sense, constructing a Model for our problem, and seeking to describe the true situation with this highly accurate, de-noised, interpretable and explainable model.
The Wave Operator and the Generalized Bloch Equation
How do we relate our Model Space back to actual data clusters? We have measured the correlations between our features and formed the matrix
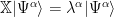

We assume there exists a operator 


Moreover, we seek to model the semantic similarity between the model features
We therefore need a way to relate the Wave Operator to our Effective (Semantic Similarity) Operator; we will achieve this via the Generalized Bloch Equation
We define the Effective Operator as an operator that acts on the model space functions and generates the associated eigenvalues of the feature-feature correlation matrix

If multiply both sides of this by $ \Omega $ , we obtain
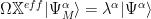
We can also insert
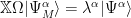
We can combine these equations as
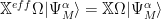
Since this expression holds for all model space functions (for all 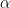
The Generalized Bloch Equation
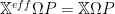
But we need one more constraint or relation to obtain the complete for our Effective Operator. And we have it. We apply what is called
Intermediate Normalization
We require that our model functions and our actual functions overlap, and we set this overlap to one
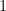
If we multiply P to the R.H.S. of the Generalized Bloch Equation, we obtain our final expression:

We now need a way to compute the Effective Operator…which brings us to
Many Body Perturbation Theory
As with many numerical matrix methods, to solve our Effective Operator equation, we decompose
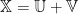
For example, in many method, 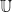
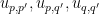

We will chose a partitioning that reflects both our physical knowledge of the system and our noise. In particular, we will assume 
Indeed, rather than Regularize, which is the standard Machine Learning approach, we will assume that we can treat the noise using low-order perturbation theory, and 1 or more adjustable parameters.
We can now re-write the Effective Operator in Partitioned Form

We can also directly express
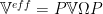
the Partitioned Form of the Generalized Bloch Equation

and, in terms of
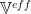

We will now solve this equation using a low order Perturbation Theory.
Let us express
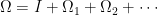
Since we only need a low order , approximate solution, we will form the so-called “second order” Effective Hamiltonian, which will take the form

We achieve this by forming an order-by-order expansion.
Let us assume, without loss of generality, that the P-space eigenvalues of 
$latex (\lambda_{0}-\mathbb{U})\Omega P=Q\mathbb{V}\Omega P-\chi PV\Omega P $
where

We shall solve this by means of a Resolvent Operator.
Please stay tuned…this will take a while to finish….and to get the Latex formatting to work properly!
The Resolvent Operator Requires it’s own Blog Post so I will go do that first, then come back
“The aim of language…is to communicate…to impart to others the results one has obtained…As I talk, I reveal the situation…I reveal it to myself and to others in order to change it.” Jean-Paul Sartre
