I a previous post, I introduced the Effective Regression Operator 
I believe this is the first time that the Effective Operator / Hamiltonian has been introduced into Machine Learning. (although I don’t know the whole field, this is basically an idea I came up with in 2001 back in the first bubble when I first got into machine learning)
Before we jump in, let me provide some motivation
One the most popular machine learning algorithms for text clustering is Latent Semantic Analysis (LSA). Given a collection of documents, we construct a term-document matrix

where the rows 
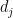
In LSA, we form the Singular Value Decomposition (SVD) of the term-document matrix, 
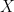

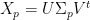

LSA uses 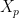

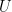


As before, define the projection operators 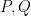

To recover LSA, we construct the
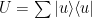
and write
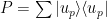

Finally, set the hidden variable block 
More generally, we can define
Consider an extended LSA problem, where we have 2 kinds of features: tags and text. Indeed, it is very common to have labelled documents, and frequently we can use these labels to help guide a text clustering algorithm (as in Labelled LDA)
Suppose we want to compute the semantic similarity between the tags explicitly, and we want to include the text as hidden variables.
We could, for example, collect all the tags and text into a single feature set of terms, run LSA on the entire term-document matrix, and compute the tag-tag semantic similarity 
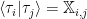
How can we include the effect of the text, the hidden variables, on the tag-tag similarity? Typically in machine learning, we apply the ‘Kernel Trick’ to form
>where 
What is 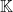


Suppose the text was not included in the LSA calculation. Then


We now construct a new, effective operator, 
Let us partition our feature space into visible (tag) features, and hidden (text) features, such that
Now write the eigenvalue equation above as
![[\begin{array}{cc} P\mathbb{X}P & P\mathbb{X}Q\\ Q\mathbb{X}P & Q\mathbb{X}Q \end{array}]\begin{array}{c} Px\\ Qx \end{array}= \lambda\begin{array}{c} Px\\ Qx \end{array}](https://s0.wp.com/latex.php?latex=%5B%5Cbegin%7Barray%7D%7Bcc%7D++++P%5Cmathbb%7BX%7DP+%26+P%5Cmathbb%7BX%7DQ%5C%5C++++Q%5Cmathbb%7BX%7DP+%26+Q%5Cmathbb%7BX%7DQ++++%5Cend%7Barray%7D%5D%5Cbegin%7Barray%7D%7Bc%7D++++Px%5C%5C++++Qx++++%5Cend%7Barray%7D%3D+%5Clambda%5Cbegin%7Barray%7D%7Bc%7D++++Px%5C%5C++++Qx++++%5Cend%7Barray%7D++++&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
We now re-write this using subscripts, and identify the expressions for the P and Q space

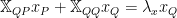
We can now find an expression for 

and plug this into (2) to obtain our Eigenvalue-Dependent Effective (Semantic) Operator

We can now compute an ‘exact’, or complete semantic similarity, between our visible features (tags) , and that also couples the hidden variables, (text) as
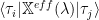
Notice that 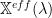

In our next post, I will address these issues, and introduce an Eigenvalue-Independent Effective (Semantic) Operator. Stay tuned
