I am frequently asked, why does weightwatcher work ?
The weightwatcher tool uses power law fits to model the eigenvalue density 
![\rho(\lambda)\sim \lambda^{-\alpha},\;\;\;\lambda\in[\lambda_{min},\lambda_{max}]](https://s0.wp.com/latex.php?latex=%5Crho%28%5Clambda%29%5Csim+%5Clambda%5E%7B-%5Calpha%7D%2C%5C%3B%5C%3B%5C%3B%5Clambda%5Cin%5B%5Clambda_%7Bmin%7D%2C%5Clambda_%7Bmax%7D%5D&bg=ffffff&fg=%23000000&s=0&c=20201002)
The average power-law exponent 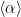
Why can we model the weight matrices of DNNs using power law fits ?
In theoretical chemistry and physics, we know that strongly correlated, complex systems frequently display power laws.
In many machine learning and deep learning models, the correlations also display heavy / power law tails. After all, the whole point of learning is to learn the correlations in the data. Be it a simple clustering algorithm, or a very fancy Deep Neural Network, we want to find the most strongly correlated parts to describe our data and make predictions.
For example, in strongly correlated systems, if you place an electron in a random potential, it will show a transition from delocalized to localized states, and the spectral density will display power law tails. This is called Anderson Localization, and Anderson won the Nobel Prize in Physics for this in 1977. In the early 90s, Cizeau and Bouchaud argued that a Wigner-Levy matrix will show a similar localization transition, and since then have modeled the correlation matrices in finance using their variant of heavy tailed random matrix theory (RMT). Even today this is still an area of active research in mathematics and in finance.
In my earlier days as a scientist, I worked on strongly correlated multi-reference ab initio methods for quantum chemistry. Here, the trick is to find the right correlated subspace to get a good low order description. I believe, in machine learning, the same issues arise. For this reason, I also model the correlation matrices in Deep Neural Networks 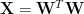
Here I will show that the simplest machine learning model, Latent Semantic Analysis (LSA), shows a localization transition, and that this can be used to identify and characterize the heavy tail of the LSA correlation matrix.
Latent Semantic Analysis: a simple example of power law correlations
Take Latent Semantic Analysis (LSA). How do we select the Latent Space? We need to select the top-K components of the TF-IDF Term-Document matrix 

We call ths plot the Empirical Spectral Density (ESD). This is just a histogram plot, on a log scale, of the eigenvalues 
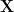

and the eigenvalues of 
We fit the eigenvalues to a power law (PL) using the python powerlaw package, which implements a standard MLE estimator.
fit = powerlaw.fit(eigenvalues)
The fit selects the optimal xmin=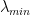
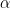

We can evaluate the quality of the PL fit by comparing the ESD and the actual fit on log-log plot.

The blue solid line is the ESD on a log-log scale (or the PDF), and the blue dotted line is the PL fit. (The red solid line is the empirical CDF, and the red dotted line the fit). The PDF (blue) shows a very good linear fit up, except perhaps for largest eigenvalues, 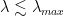

We can get even more insight into the quality of the fit by examining how the PL method selected xmin
xmin:

The optimization landscape is convex, with a clear global minimum at the orange line, which occurs at the 
To form the Latent space, we select these largest 547 eigenpairs, to the right of the orange line, the start of the (truncated) power-law fit
The Localization Transition
To identify the localization transition in LSA, we can plot localization ratios 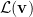

def localization_ratio(v):
return np.linalg.norm(v, ord=1) / np.linalg.norm(v, ord=np.inf)
We see that get an elbow curve, and the eigenvalue cutoff appears just to the right of the ‘elbow’:

Other methods include looking scree plots or even just the sorted eigenvalues themselves.
Comparison with other K-selection methods
Typically, in unsupervised learning, one selects the top-K clusters, eigenpairs, etc. by looking at some so-called ‘elbow curve’, and identifying the K at the inflection point. We can make these plots too. A classic way is to plot the explained variance per eigenpair:

We see that the power-law 
Conclusion
I suspect that in these strongly correlated systems, the power law behavior really kicks it right at / before these inflection points. So we can find the optimal low-rank approximation to these strongly correlated weight matrices by finding that subspace where the correlations follow a power-law / truncated power law distribution. Moreover, we can detect, and characterize these correlations, by both the power-law exponent 
And AFAIK, this has never been suggested before.
