We consider a very common example of Machine Learning problem as an application to the Effective Operator Framework: Simple SemiSupervised Learning
Suppose we have N documents that we could like to classify into K categories. If every document is labelled (say 1-K), then it is straightforward to train a muli-class classifier to do this, such as a multi-class SVM using a package like liblinear. In many cases, however, we only a small subset of the documents are labelled. Here, one can use a semi-supervised or Transductive SVM (such as svmlight, svmlin, etc.). This seems straightforward until you realize that the semi-supervised algorithms are non-convex, making them hard to parameterize and slower to train.
Here, we show that the Effective Operator formalism provides a simple semi-supervised learning algorithm. Indeed, this was the original motivation for the formulation. Still, the formalism presented is suited for regression, not classification, but we ignore this detail for now.
Indeed, there are many text regression problems suitable for semi-supervised learning. We might have P web pages, and we measure their search volume (average number of page views). We then want to predict traffic for new documents we create. Or, suppose we have P text ads, and we want to predict the number clicks. And so on
These days, SemiSupervised learning is said and done, and has even been applied to tens of millions of images .
We would like to train a machine learning model that can predict some continuous label / value for a new document D. Suppose we have N documents, but only labels (y) for P of them. Let 

and write our machine learning problem as trying to find the optimal weight vector 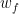

We now apply the Effective Operator formalism. We need to find a partitioning of the feature space

so that the Q-space features 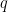
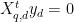
or, really, just that the Q-space correlations are much smaller than the P-space correlations,
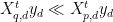
That is, we need to search the space of possible choices of the Q-space to achieve this. Generally speaking, this search could be unbounded, since the Q-space could consist of all possible linear (or non-linear) transformations on 

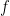
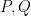

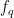


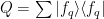
The optimal partitioning (what words are actually relevant and not) could be accomplished with a brute force search, although it is probably better to apply a gradient-search algorithm–ideally a convex optimization. Practically speaking, one could just run an L1 SVM regression (using the latest version of liblinear) on the labeled documents, and select the features with non-zero weights as the P-space . The Effective Operator would then provide a way to incorporate correlations with unseen features (words) — a kind of prior language model — into the labelled training set in a simple way.
I will eventually work out an iPython notebook to explore this. Also, I believe this recent paper is very close to the same idea: Transductive Multilabel Learning via Label Set Propagation

I might be confused with P-U learning or your post on Transductive SVMs here ,
But what do you mean: “select the features with non-zero weights as the P-space” ?
My understanding is that you’d be adding samples to your training sets/data, what do features have to do with that?
(Do you mean some sort of feature selection/adding features from newly classified instances in the case of words as features ?)
D.
LikeLike
yes, as a feature selection method
I mean to use the L1-SVM for feature selection
we should just try the idea out and see if it works
I worked out a lot of these ideas 15 years ago, before
L1 SVMs existed
LikeLike