Recently, Meta released LLama3.2 1B and 3B Instruct Fine Tuned LLM. To mixed reviews. On the one hand, it’s ranking ~100 on the Chatbot Arena (formerly LMSYS). On the other hand, it outperforms the older Falcon 180B! But there is something more curious about it
Llama3.2 is the first *major* fine-tuned instruct model I have seen so far that does not follow the weightwatcher / HTSR theory. (Far more under-trained layers, maybe less over-trained)

Here we examples from Llama3.1, Falcon, Mistal7B, Qwen2, and Solar. The smallest Llama3.2 models are shown on the bottom row.
WeightWatcher: Diagnosing Fine-Tuned LLMs
In previous blog posts, we have examined:
- What’s instructive about Instruct Fine-Tuning: a weightwatcher analysis, and how to
- Evaluate Fine-Tuned LLMs with WeightWatche
Briefly,when you run the open source weightwatcher tool on your model, it will give you layer quality metrics for every layer in your model. And the fine-tuned component (i.e. the adapter_model.bin, if you have it. Or it will reconstruct it for you).
You can then plot the layer quality metric alpha $( \alpha &bg=ffffff )$
- as an alpha histogram (with warning zones), or
- layer-by-layer: i.e. a Correlation Flow plot, or
- alpha-vs-alpha: comparing the FT part to the base model
Or, if you like, I can run your model for you in the new up-and-coming WeightWatcher-Pro and give you a free assessment:

For now, let’s take a look in some detail as to what’s going on.
LLama3.2 11B vs 90B: Large models still follow the HTSR theory
The first question: is this only for the smaller models or do the larger LLama3.2 models also show this. And it turns out, yes, this is only for LLama3.2 1B, 3B. Less but a little for 11B. And not at all in 90B
The odd alpha plots with LLama3.2 1B and 3B do not appear in the larger Llama3.2-90B-Vision-Instruct (left). Especially when compared to the smaller LLama3.2-11B-Vision-Instruct model (right)

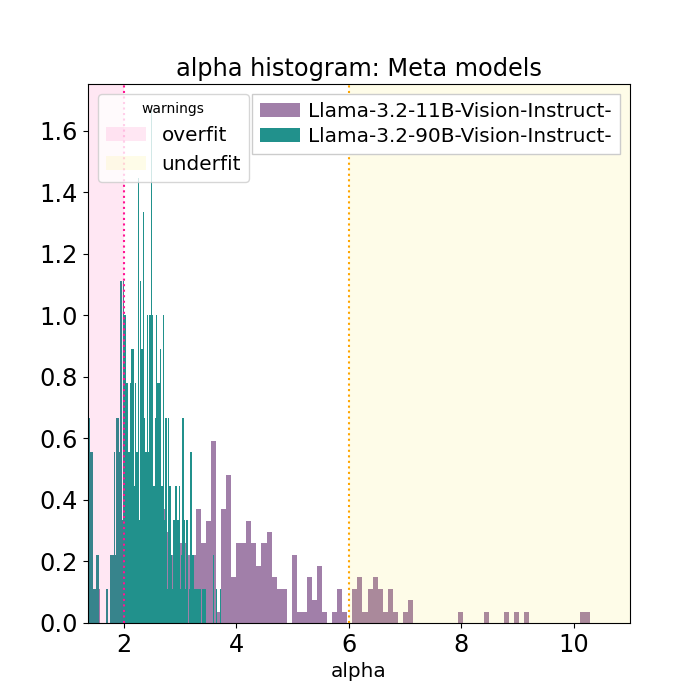
In the left-hand plot, we see that the weightwatcher layer alphas plotted as a histogram; almost all the layer alphas lie within 2 and 4. Although there are some alpha < 2. And a few alpha=0 (which indicates the layer is malformed. This indicates that all of the layers in Llama3.2-90B-Vision-Instruct are fully trained, and maybe some over-trained. But there are not that many over-trained.

In contrast, as shown in the right-hand plot, the Llama3.2-11B-Vision-Instruct layers have larger alphas on average, continuously ranging up to 6-7 and a few upto 8-10.
These results show that the average alpha is smaller for LLama3.2-90B than 11B, and the 11B shows a few overtrained layers. As expected with the HTSR theory.
Smaller is weirder
As the Llama3.2 models get smaller, from 11B to 3B, the average layer alpha gets larger, and there are many more layer alpha greater than 6.
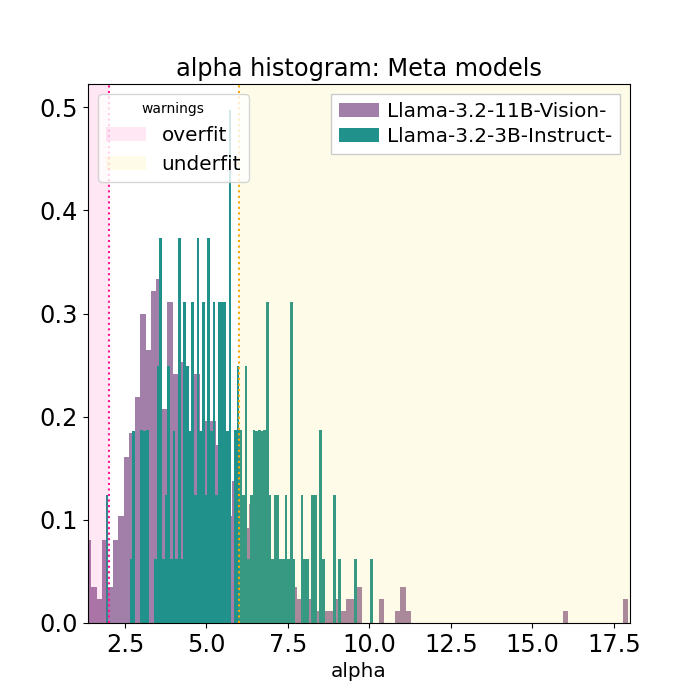
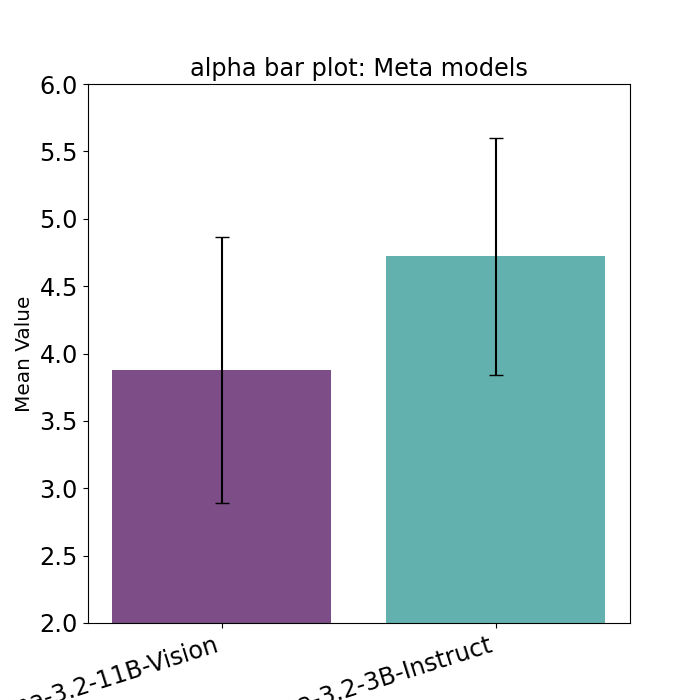
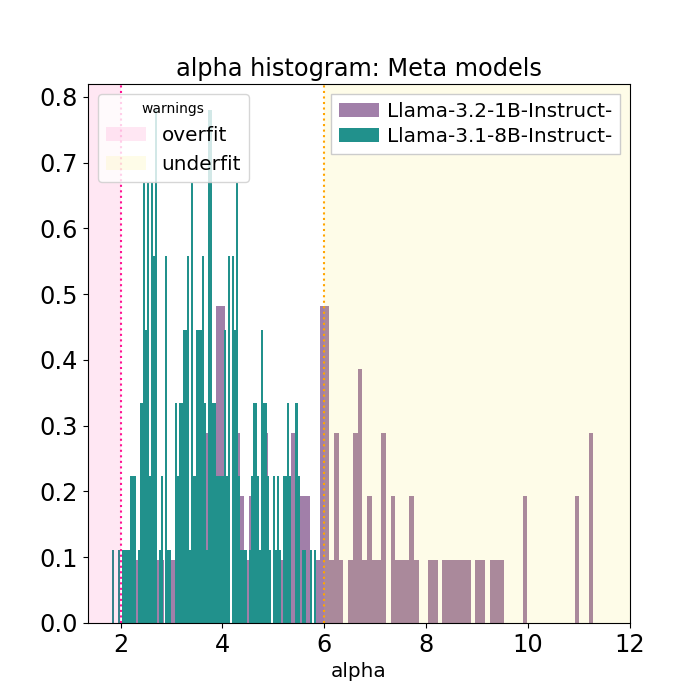
And while theory suggests that smaller models to have larger alphas, these plots are unique for the Llama3.2 models. For example, comparing Llama3.2-1B and 3B FT instruct parts to the admittedly larger Llama3.1-8B case, the weightwatcher alpha histogram plots are quite different!

Other Smaller Models are Not always Weird: Qwen2-05B-Instruct

The results above might suggest that the Llama3.2 1B and 3B models look weird simply because they are small, but other smaller models do NOT look like this. In particular, the Qwen2-0.5B-Instruct model looks just fine. Here’s an example you can find on the weightwatcher.ai landing page
Comparing the Qwen2-05B-Instruct model to its base, the layer alphas look great!
Whats going on in Llama3.2 ?
The key differences between Llama 3.2 and Llama 3.1 models, particularly the 1B and 3B versions, include:
- Improved Efficiency: Llama 3.2 models have been optimized for better computational efficiency, making them faster and less resource-intensive during both training and inference compared to Llama 3.1 models.
- Model Architecture Enhancements: Llama 3.2 introduces refinements in model architecture, such as improved layer normalization and better attention mechanisms, leading to enhanced performance, especially in tasks requiring nuanced language understanding.
- Inference Speed: Llama 3.2 models are more optimized for faster inference times, making them ideal for applications where speed is critical, such as real-time or edge
and, most importantly - Fine-Tuning and Generalization: Llama 3.2 models are designed with better fine-tuning capabilities, allowing for more effective adaptation to specific downstream tasks while maintaining strong generalization across a broader range of applications. deployments.
It’s possible that having more under-trained layers makes Llama3.2 easier to fine-tune because if all the layers have alpha~2, then the fine-tuned layers are more likely to be overfit. To that end, it will be very instruct to analyze fine-tuned versions of Llama3.2 1B and 3B as they become available.
The WeightWatcher Pitch
Fine-Tuning LLMs hard. WeightWatcher can help. WeightWatcher can tell you if your Instruct Fine-Tuned model is working as expected, or if something odd happened during training. Something that can not be detected with expensive evaluations or other known methods
WeightWatcher is a one-of-a-kind must-have tool for anyone training, deploying, or monitoring Deep Neural Networks (DNNs).
I invented WeightWatcher to help my clients who are training and/or fine-tuning their own AO models. Need help with AI ? Reach out today. #talkToChuck #theAIguy
