Evaluating LLMs is hard. Especially when you don’t have a lot of test data.
In the last post, we saw how to evaluate fine-tuned LLMs using the open-source weightwatcher tool. Specifically, we looked at models after the ‘deltas’ (or updates) have been merged into the base model.
In this post, we will look at LLMs fine-tuned using Parameter Efficient Fine-Tuning (PEFT), also called Low-Rank Adaptations (LoRA). The LoRA technique lets one update the weight matrices (W) of the LLM with a Low-Rank update (BA):
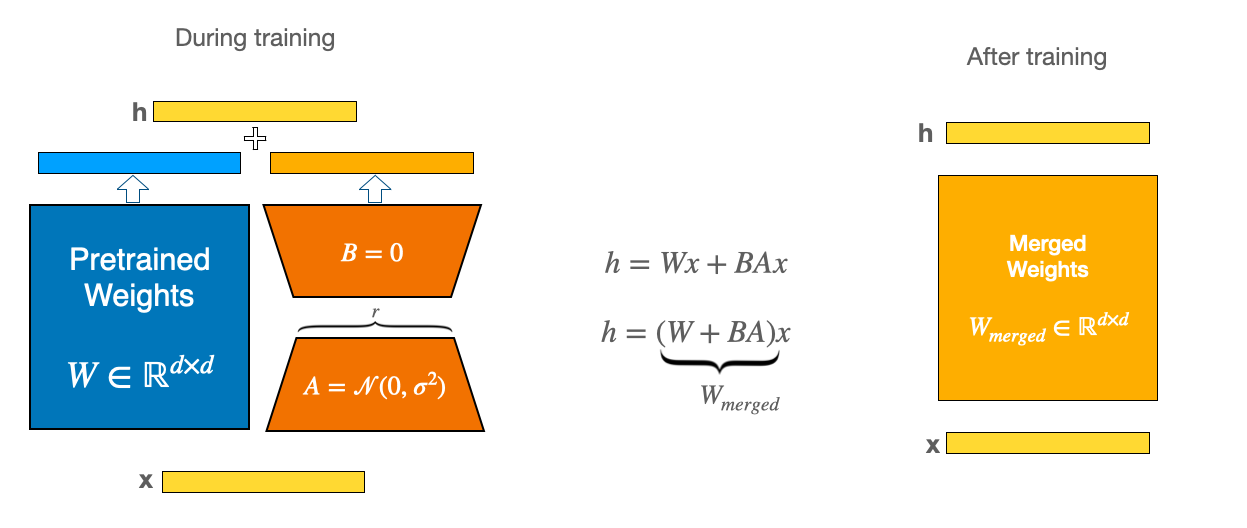
Here is a great blog post explaining all things LoRA
The A and B matrices are significantly smaller than the base model W matrix, and since many LLMs are quite large and require a lot of disk space to store, it is frequently convenient to only store the A and B matrices. If you use the HuggingFace peft package, you would then store these matrices in a file called either
- adapter_model.bin, or
- adapter_model.safetensors
These adapter model files can be loaded directly into weightwatcher so that the lora BA matrices can be analyzed separately from the base model. To do this, use the peft=True option. But first, lets check the requirements on the model for doing this
0.) Requirements for PEFT/LoRA models
–
- The update or delta should either be either loaded in memory, or stored in a directory/folder, and in the pytorch or safetensors format
- The LoRA rank (r) should be r>10, otherwise you need to also specify min_evals=2
- The LoRA layer names for the A and B matrix updates should include the tokens ‘lora_A’ and/or ‘lora_B’
- We do not specifically support the LighteningAI Lit-GPT framework yet
- the weightwatcher version should now be 0.7.4.3 or higher
Here’s a Google Colab Notebook with the code discussed below
1) A simple example: llama-7b-lora
To illustrate the tool, we will use this Llama-7b LoRa fine-tuned model . You may download this model.
!git clone https://huggingface.co/DevaMalla/llama_7b_lora
The llama-7b-lora directory should have the adapter_model.bin file

2) Describe the model
I recommend you first check the model to ensure weightwatcher reads the model file correctly and finds all the layers.
2a) peft=False
First, lets see what the raw model looks like
import weightwatcher as ww
watcher = ww.WeightWatcher()
details = watcher.describe(model='llama_7b_lora')
Note: if you don’t specify left-=True, then weightwatcher will try analyze the individual A and B matrices, which is NOT what you want. But we can check that the layer names. The details dataframe should look like this:
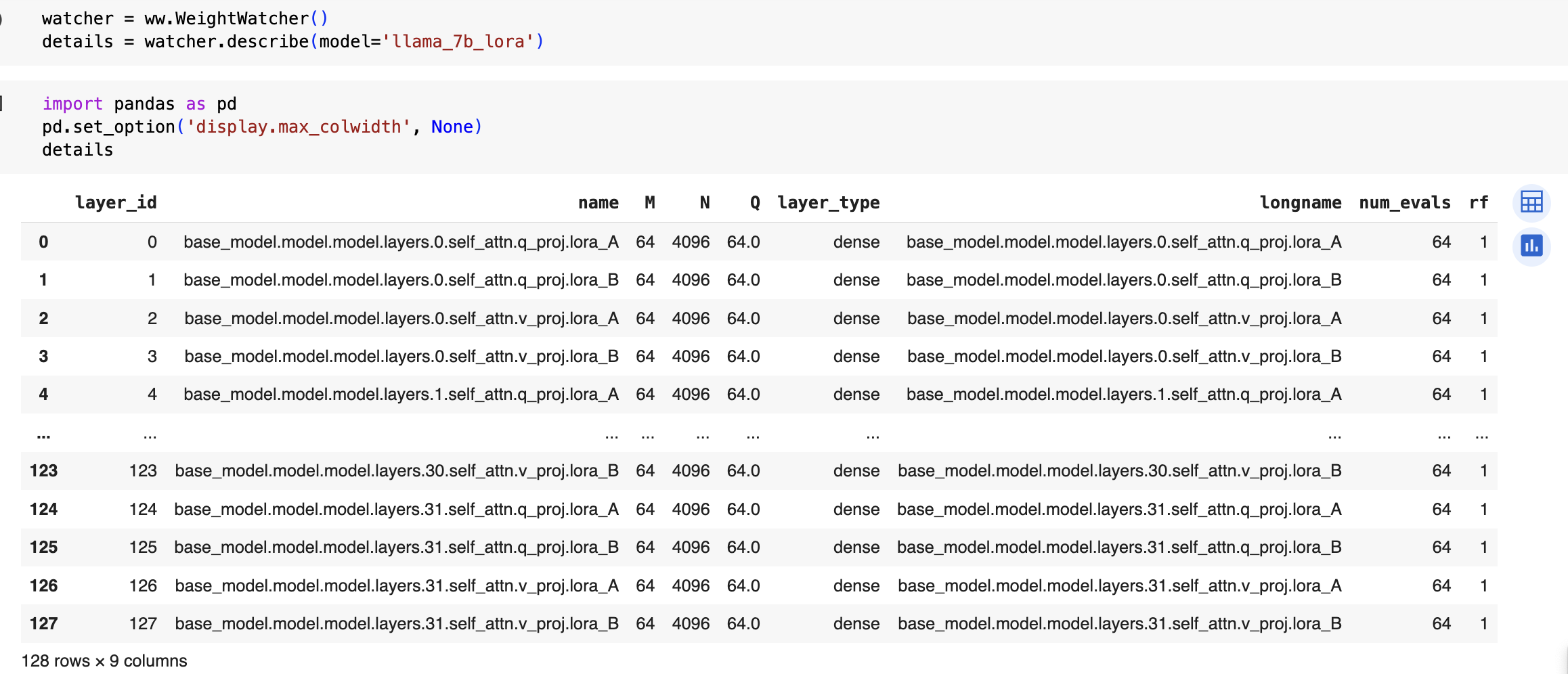
Notice that this dataframe has 128 rows, and each layer name has the phrase ‘lora_A’ or ‘lora_B’ in it.
Also, notice that the matrix rank for A and B is M=64, which is large enough for weightwatcher to get a good estimate of the weightwatcher layer quality metric alpha
2a) peft=True
watcher = ww.WeightWatcher()
details = watcher.describe(model='llama_7b_lora', peft=True)
The peft=True dataframe now should look like this:

Now we see that the details dataframe has only 64 rows, and each layer name has the phrase ‘lora_BA‘ in it. Each layer now represents the 
Note: we use the notation from the original LoRa paper, whereas other blogs and frameworks may use $latex \Delta \mathbf{W}=\mathbf{AB}$
3) Analyze the adapted_model.bin
watcher = ww.WeightWatcher()
details = watcher.analyze(model='llama_7b_lora', peft=True)
The details dataframe should now contain useful layer quality metrics such as alpha, alpha_weighted, etc. Here’s a peek:

We can now look at some of these metrics to see how well our LoRA fine-tuning worked.
3.a) Heavy-Tailed Layer Quality Metric alpha
Let’s plot a histogram of the Power law exponenent metric alpha.
import matplotlib.pyplot as plt
avg_alpha = details.alpha.mean()
title=f"Fine Tuned WeightWatcher Alpha\n Llama-7b-LoRA"
details.alpha.plot.hist(bins=50)
plt.title(title)
plt.axvline(x=avg_alpha, color='green',label=f"<alpha> = {avg_alpha:0.3f}")
plt.legend()

Notice that all of the layer alphas are less then 2 (alpha < 2). That is, al the layer ESDs live in the HTSR Very Heavy Tailed (VHT) Universality Class--which could be problematic. Typically, with well-performing models, we see alpha in [2.4], and we very rarely find alpha < 2. And this holds for the 
We have found that for many LoRA fine-tuned, the alphas < 2. What does it mean when a layer alpha < 2 ?
- the layer is over-regularized ?
- the layer could be overfitting its training data ?
We could potentially prevent these small alphas by decreasing the learning rate.
4) LoRA alphas vs Base Model alpha
Why are the LoRA layer alphas so small ? Are these layers overfitting their training data ? This remains an open question, but we can get some insights by comparing the LoRA layer alphas to the corresponding layers in the base model. Notice that in this model, the developer only fine tuned the Q and V layers.
If we have the base_model details for the llama_7b model , we can compare the layer alphas between the Base and the fine-tuned LoRA models
B = base_details
filtered_B = B[B['name'].str.contains('q|v', na=False)]
base_alphas = filtered_B.alpha.to_numpy()
lora_alphas = details.alpha.to_numpy()
plt.scatter(x=base_alphas, y=lora_alphas)
plt.title("Llama-7b: LoRA alphas vs Base Model alphas")
plt.xlabel("Base Model Layer alpha")
plt.xlabel("Lora Layer alpha")

From this plot, we see immediately that the larger the Base model alphas are, the smaller the LoRA layer alphas are. This is a common pattern we have observed in other LoRA models, and is easy to reproduce even when fine-tuning a small model like BERT. (for a future blog post)
What does this mean ? It appears that the when the base model layer is less correlated (alpha > 6 say), the LoRA update tends to be more correlated. It is as if the LoRA fine-tuning procedure over-fits its training data when the layer being adapted is not well trained.
This is quite curious and suggests that one has to be very careful when fine-tuning base models like Llama with many under-correlated layers (i.e. alpha > 6). In contrast, the Falcon models do not show such behavior (see the weightwatcher LLM leaderboard page).
On the other hand, maybe this is not a bad thing, and you actually want your fine-tuned LLM to overfit / memorize your training data as much as possible ?
5) Next Steps
If you want to try this yourself:
pip install weightwatcher
and join our Community Discord channel to discuss the results and explore this and other features of the weightwatcher tool.

1 Comment