Recently Facebook hired Vapnik, the father of the Support Vector Machine (SVM) and the Vapnik-Chrevoniks Statistical Learning Theory.

Lesser known, Vapnik has also pioneered methods of Transductive and Universum Learning. Most recently, however, he has developed the theory of the Learning Using Privileged Information (LUPI), also known as the SVM+ method.
And this has generated a lot of interest in the community to develop numerical implementations.
In this post, we examine this most recent contribution.
Preface
Once again, we consider the problem of trying to learn a good classifier having a small set of labeled examples 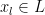
Here, we assume we have multiple views of the data; that is, different, statistically independent feature sets 
For example, we might have a set of breast cancer images, and some holistic, textual description provided by a doctor. Or, we might want to classify web pages, using both the text and the hyperlinks.
Multi-View Learning is a big topic in machine learning, and includes methods like SemiSupervised CoTraining, Multiple Kernel Learning, Weighted SVMs, etc. We might even consider Ensemble methods as a kind of Multi-View Learning.
Having any extra, independent info 
In LUPI, also called the SVM+ method, we consider situation where we only have extra information 
Vapnik calls 
The VC Bounds
If we are going to discuss Vapnik we need to mention the VC theory. Here, we note an important result about soft and hard-margin SVMs: when the training set is non-separable, the VC bounds scale as 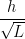

where 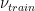
But when the training set is separable, i.e. 

This means we can use say L=300 labeled examples as opposed to L=900,000, which is a huge difference.
It turns out we can also achieve 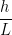
So if we can get the slacks 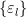
[Of course, this is only true if we can sample all the relevant features.]
Soft Margin SVM
In practice, we usually assume data is noisy and non-separable. So we use a soft-margin SVM where we can adjust the amount slack with the 
Note that we also have the bias 
Let us write the soft-margin SVM optimization as
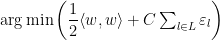
subject to the constraints
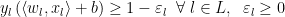
Notice that while we formally add slack variables
![\hat{err_{l}}=\max[1-y_{l}(\langle w,x_{l}\rangle+b,0)]](https://s0.wp.com/latex.php?latex=%5Chat%7Berr_%7Bl%7D%7D%3D%5Cmax%5B1-y_%7Bl%7D%28%5Clangle+w%2Cx_%7Bl%7D%5Crangle%2Bb%2C0%29%5D+&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
We then solve the unconstrained soft-margin SVM optimization, which is a convex upper bound to the problem stated above–as explained in this nice presentation on LibLinear.
![\arg\min\left(\dfrac{1}{2}\langle w,w\rangle+C\sum_{l\in L}\max[1-y_{l}(\langle w,x_{l}\rangle+b,0)]\right)](https://s0.wp.com/latex.php?latex=%5Carg%5Cmin%5Cleft%28%5Cdfrac%7B1%7D%7B2%7D%5Clangle+w%2Cw%5Crangle%2BC%5Csum_%7Bl%5Cin+L%7D%5Cmax%5B1-y_%7Bl%7D%28%5Clangle+w%2Cx_%7Bl%7D%5Crangle%2Bb%2C0%29%5D%5Cright%29+&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
or, in simpler terms

And this works great–when we have lots of labeled data L.
What if we could actually estimate or assign all the L slack variables
LUPI/SVM+
In LUPI, we use the privileged information 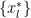

We model the slack as linear functions of the privileged information.
Effectively, the privileged information provides a measure of confidence for each labeled instance.
To avoid overtraining, we apply a max-margin approach. This leads to an extended, SVM+ optimization problem, with only 2 adjustable regularization parameters 
![\arg\min\left(\dfrac{1}{2}\langle w,w\rangle+\dfrac{\gamma}{2}\langle w^{*},w^{*}\rangle+C\sum_{l\in L}[\langle w^{*},x_{l}^{*}\rangle+b^{*} ]\right)](https://s0.wp.com/latex.php?latex=%5Carg%5Cmin%5Cleft%28%5Cdfrac%7B1%7D%7B2%7D%5Clangle+w%2Cw%5Crangle%2B%5Cdfrac%7B%5Cgamma%7D%7B2%7D%5Clangle+w%5E%7B%2A%7D%2Cw%5E%7B%2A%7D%5Crangle%2BC%5Csum_%7Bl%5Cin+L%7D%5B%5Clangle+w%5E%7B%2A%7D%2Cx_%7Bl%7D%5E%7B%2A%7D%5Crangle%2Bb%5E%7B%2A%7D+%5D%5Cright%29+&bg=%23ffffff&fg=%23000000&s=0&c=20201002)
subject to the constraints
![y_{l}\left(\langle w_{l},x_{l}\rangle+b\right)\ge 1-[\langle w^{*},x_{l}^{*}\rangle+b^{*}],](https://s0.wp.com/latex.php?latex=y_%7Bl%7D%5Cleft%28%5Clangle+w_%7Bl%7D%2Cx_%7Bl%7D%5Crangle%2Bb%5Cright%29%5Cge+1-%5B%5Clangle+w%5E%7B%2A%7D%2Cx_%7Bl%7D%5E%7B%2A%7D%5Crangle%2Bb%5E%7B%2A%7D%5D%2C+&bg=%23ffffff&fg=%23000000&s=0&c=20201002)

Show me the code?
The SVM+/LUPI problem is a convex (quadratic) optimization problem with linear constraints–although it does require a custom solver. The current approach is to solve the dual problem using a variant of SMO. There are a couple versions (below) in Matlab and Lua. The Matlab code includes related SVM+MTL (SVM+ MultiTask Learning). I am unaware of a open source C or python implementation similar to Svmlin or Universvm.
To overcome the solver complexity, other methods, such as the Learning to Rank method, have been proposed. We will keep an eye out for useful open source platforms that everyone can benefit from.
Summary
The SVM+/LUPI formalism demonstrates a critical point about modern machine learning research. If we have multiple views of our data, extra information available during training (or maybe during testing), or just several large Hilbert spaces of features, then we can frequently do better than just dumping everything into an SVM, holding our nose, and turning the crank.
References:
or how many ways can we name the same method?
Learning with Hidden Information
The SVM+ method: MIT Reading Notes
Learning with Non-Trivial Teacher
Learning to Rank Using Privileged Information
On the Theory of Learning with Privileged Information
SMO-style algorithms for learning using privileged information
Learning Using Privileged Information: SVM+ and Weighted SVM
Learning with Asymmetric Information
Comparison of SVM+ and related methods (SVM+MTL, rMTL, SVM+ regression, etc.)
Videos
Learning with Privileged Information

I’ve transformed the C/C++ code developed by Dmitry Pechyony into a Matlab mex interface similar to the one provided by LIBSVM package:
https://github.com/okbalefthanded/conj-svm-plus-mex
LikeLike